강화학습 기반 마이크로그리드 control - 4) DDPG를 이용한 ‘continuous’ control 도출
실제로는 수전/송전이 continuous action임에도, Vincent의 마이크로그리드 사례에선 ‘discrete’ action (1.1kW 수전/ 1.1kW 송전/ idle)으로도 충분히 economic control이 가능했다. 그렇다면, continuous action을 다루는 심층강화학습 기법을 적용하면 더 우수한 economic control이 가능할 지 궁금해진다.
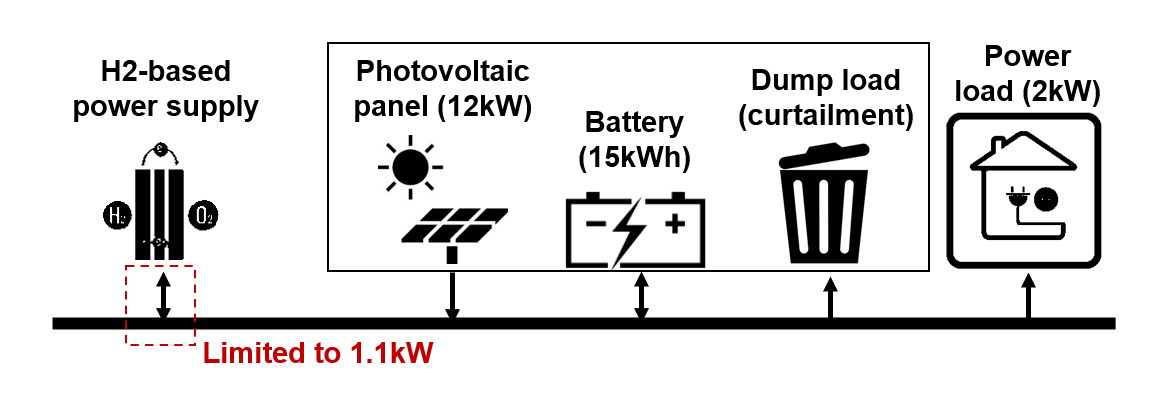 Vincent의 연구에서 가정된 마이크로그리드.
Vincent의 연구에서 가정된 마이크로그리드.
이번에는 continuous control의 기본적인 방법인 Deep Deterministic Policy Gradient (DDPG)를 적용해서, 수전/송전에 대한 continuous control을 도출해본다.
Actor와 critic 신경망
Continuous action인 경우 가능한 action의 수가 사실상 무한대이므로, DQN에서처럼 state를 입력받아 각 action 별 Q-value를 모두 계산하는 신경망을 구성할 수는 없다.
대신에, 두 개의 신경망을 구성하되 하나는 state를 입력받고 continuous action의 값을 출력하고, 다른 하나는 state와 action을 입력받아 그 state-action pair의 Q-value를 출력하도록 한다. 두 신경망 중 전자를 actor (action을 결정함), 후자를 critic (value를 평가함) 이라 부른다.
이 때 actor는 state를 받고 deterministic한 action을 출력하는 policy로 볼 수 있다. 그래서 이 방법에는 Deep Deterministic Policy Gradient (DDPG) 라는 이름이 붙었다.
특히 이 마이크로그리드 사례에서 action은 하한이 -1.1, 상한이 1.1로 정해져 있다. 이러한 ‘bounded’ action을 구현하기 위해, actor의 output layer에 tanh (하이퍼볼릭 탄젠트) activation function을 걸어준다.
Target 신경망
한편, DDPG에서는 ‘target’ 신경망을 구성해서 학습의 안정성을 향상시킨다. Actor와 critic 각각의 target 신경망들은 원래 actor와 critic의 복사본으로 시작해서, Q-learning에서 next state에 대한 값을 도출하는 데 이용된 후 천천히 업데이트된다.
구체적으로, 원래 신경망들의 parameter를 $\theta$, target 신경망들의 parameter를 $\theta’$라 하고, 원래 actor와 target actor를 각각 $\mu(s)$와 $\mu’(s)$, 원래 critic과 target critic을 각각 $Q(s,a)$와 $Q’(s,a)$라 하자.
그러면, critic 신경망 훈련 시의 목적함수는 $Q(s_{t},a_{t})$와 $r_{t+1} + \gamma \text{max}_{\mu’} Q’(s_{t+1},\mu’(s_{t+1}))$ 간 차이의 평균제곱합이다. 두 번째 항이 target 신경망에 의해 계산되었음에 주목한다.
한편 actor 신경망 훈련 시의 목적함수는 $-Q(s_{t},\mu(s_{t}))$, 즉 음의 Q-value이다. Actor는 Q-value를 최대화하는 action을 도출해야 하기 때문이다. Actor 훈련 시의 목적함수는 target 신경망에 의해 계산되지 않았다.
원래 critic과 actor에 대해 가중치 업데이트를 수행한 후, target critic과 actor에 대한 가중치 업데이트는 작은 양수 $\tau$에 대해 아래와 같이 수행한다. $\tau$가 작으므로 (대략 0.05 전후), $\theta’$는 ‘느리게’ 업데이트된다.
$\theta’ \leftarrow \tau \theta + (1-\tau) \theta’$
왜 target 신경망을 쓰면 학습의 안정성이 향상되는 것일까?
Q-learning에서는 $q_{\ast}(s_{t},a_{t})$에 대한 두 추정치 $Q(s_{t},a_{t})$와 $r_{t+1} + \gamma \text{max}_{a_{t+1}} Q(s_{t+1},a_{t+1})$가 말 그대로 ‘둘 다 추정치’이다.
즉 추정치를 추정치 기반으로 추정한다 (이를 bootstrap이라고도 한다). 이 때문에, 운 나쁘게 추정이 잘못된 방향으로 진행되기 시작하면, 훈련이 발산해버리기 쉽다.
Target 신경망 구성을 통해, 두 추정치 중 후자의 변화를 완화하면, 훈련이 발산할 가능성을 크게 줄일 수 있다.
(보다 더 상세한 내용은 논문 원문을 참고하길 바란다)
DDPG 코드
이제 DDPG를 적용하여 continuous controller를 훈련하는 코드를 보자 (해당 코드 작성에 참고한 DDPG 코딩 설명 포스트). 코드 내 주석은 지난 포스팅의 DQN 코드 대비 다른 부분에 대해서만 추가하였다. (GitHub Repo 링크)
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Dense, Conv1D, concatenate, Flatten
import time
### hyperparameters
actor_lr = 0.0005 # actor NN의 learning rate
critic_lr = 0.001 # critic NN의 learning rate
tau = 0.05 # target NN 업데이트 속도 조절 계수
rewardscalefactor = 1
buffer_size = 20000
batch_size = 32
discount_factor = 0.98
period_step_fortrain = 24
### microgrid system data
PV_prod_train = np.load('BelgiumPV_prod_train.npy')
PV_prod_test = np.load('BelgiumPV_prod_test.npy')
load_train = np.load('example_nondeterminist_cons_train.npy')
load_test = np.load('example_nondeterminist_cons_test.npy')
prate_h2 = 1.1
eff_h2 = 0.65
capa_batt = 15
eff_batt = 0.9
initialenergy_batt = 0.0
price_h2 = 0.1
cost_loss = 2
load_peak = 2
pv_peak = 12
inputlen_load = 24
inputlen_pv = 24
### Neural net configuration
class Critic(tf.keras.Model): # Q-value를 추정하는 NN (action이 continuous)
def __init__(self):
super(Critic, self).__init__() # tf.Keras.Model 상속받는 이유는 main코드에서 get_weights, set_weights 등을 매번 model 메서드를 불러오지 않고도 편하게 쓰기 위함
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.input_action = Input(shape=(1)) # action 값 (state 뿐 아니라 action도 input임)
self.concat_all = concatenate([self.flatten_conv,self.input_others,self.input_action])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_qval = Dense(1)(self.hidden_dense_2)
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others,self.input_action], outputs=[self.output_qval])
def call(self, input_load,input_pv,input_others,input_action): # state 뿐 아니라 action도 input임
return self.model((input_load,input_pv,input_others,input_action)) # output은 입력된 state-action pair에 대한 Q-value '단일값'
class Actor(tf.keras.Model): # (Continuous) Action을 결정하는 policy NN
def __init__(self):
super(Actor, self).__init__()
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.concat_all = concatenate([self.flatten_conv,self.input_others])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_action = Dense(1,activation='tanh')(self.hidden_dense_2) # Node 갯수는 action의 자유도이며, tanh activation은 action(충/방전) 이 [-1,1] 범위의 bounded action임을 반영함
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others], outputs=[self.output_action])
def call(self, input_load,input_pv,input_others): # state가 input임
return self.model((input_load,input_pv,input_others))
critic_one_learning = Critic()
critic_one_target = Critic() # target 신경망 정의
critic_one_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.set_weights(critic_one_learning.get_weights()) # target 신경망의 가중치의 초기값은 원래 신경망의 가중치와 같게 둠.
actor_learning = Actor()
actor_target = Actor() # target 신경망 정의
actor_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.set_weights(actor_learning.get_weights()) # target 신경망의 가중치의 초기값은 원래 신경망의 가중치와 같게 둠.
from collections import deque
replay_buffer = deque(maxlen=buffer_size)
def sample_experiences(batch_size):
indices = np.random.randint(len(replay_buffer), size=batch_size)
batch = [replay_buffer[index] for index in indices]
states, actions, rewards, next_states = [
np.array([experience[field_index] for experience in batch])
for field_index in range(4)]
return states, actions, rewards, next_states
def play_one_step(profile_load,profile_pv,hour,energy_batt,epsilon,training=False):
state = np.concatenate( (profile_load[hour-inputlen_load:hour], profile_pv[hour-inputlen_pv:hour], np.array([energy_batt])) )
if np.random.rand() < epsilon and training == True: # exploration during training
action = np.random.uniform(low=-1.0, high=1.0, size=1)[0] # exploration 시 -1~+1 사이의 실수를 균등분포에서 추출
else: # exploitation
action = actor_learning(profile_load[hour-inputlen_load:hour].reshape(-1,inputlen_load,1), profile_pv[hour-inputlen_pv:hour].reshape(-1,inputlen_pv,1), np.array([energy_batt]).reshape(-1,1)).numpy()[0][0] # action net의 output은 tensor이므로, 이를 numpy 변환 후 [0][0]으로 불러와야 int 변수가 됨
# Unscaling
p_h2_send = 0
p_h2_receive = 0
if action > 0:
p_h2_receive = prate_h2*action # 여기서 action은 전기 '수전'에 대해 양수라고 가정, action은 [-1,1] 구간의 실수이므로 prate_h2를 곱해 [-1.1,1.1] 구간의 실수가 되도록 함
else:
p_h2_send = -prate_h2*action # action은 전기 '송전'에 대해 음수
p_load = profile_load[hour]*load_peak
p_pv = profile_pv[hour]*pv_peak
energy_batt = energy_batt*capa_batt
#p_curtail = 0
p_loss = 0
p_net_beforebatt = p_pv - p_load + p_h2_receive - p_h2_send
if p_net_beforebatt >= 0:
if capa_batt >= energy_batt + p_net_beforebatt*eff_batt:
energy_batt_after = energy_batt + p_net_beforebatt*eff_batt
else:
energy_batt_after = capa_batt
# p_curtail = (energy_batt + p_net_beforebatt*eff_batt - capa_batt)/eff_batt
else:
if energy_batt*eff_batt >= -p_net_beforebatt:
energy_batt_after = energy_batt + p_net_beforebatt/eff_batt
else:
energy_batt_after = 0
p_loss = -p_net_beforebatt - energy_batt*eff_batt
reward = price_h2*p_h2_send*eff_h2 - price_h2*p_h2_receive/eff_h2 - cost_loss*p_loss
energy_batt_after = energy_batt_after/capa_batt
if training == True:
next_state = np.concatenate( (profile_load[hour-(inputlen_load-1):hour+1], profile_pv[hour-(inputlen_pv-1):hour+1], np.array([energy_batt_after])) )
replay_buffer.append((state, action, reward*rewardscalefactor, next_state))
return energy_batt_after, reward, action
def training_step(batch_size,actorupdate=True):
states, actions, rewards, next_states = sample_experiences(batch_size)
input_load = states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv = states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others = states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
input_load_next = next_states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv_next = next_states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others_next = next_states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
actions_by_target = actor_target(input_load_next,input_pv_next,input_others_next).numpy().reshape(-1,1) # nextstate에 대한 action은 target net으로 도출
actions_by_target = np.clip(actions_by_target,-1,1) # [-1,1] 범위로 제한
Q_values_one_by_target = critic_one_target(input_load_next,input_pv_next,input_others_next,actions_by_target) # nextstate에 대한 Q-value는 target net으로 도출
y = tf.stop_gradient(rewards + discount_factor * Q_values_one_by_target)
with tf.GradientTape() as tape: # critic net 업데이트를 위한 자동미분 (actor net 업데이트와 별개로 둠)
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions.reshape(-1,1)) # critic_one_learning을 gradient descent로 훈련시키려면, GradientTape 구문 내에서 현재 state-action에 대한 Q_value Tensor를 critic_one_learning으로 다시 불러와야 함
loss_critic_one = tf.reduce_mean(keras.losses.mean_squared_error(y, Q_values_one)) # 평균제곱오차 계산
grads = tape.gradient(loss_critic_one, critic_one_learning.trainable_variables)
critic_one_learning.optimizer.apply_gradients(zip(grads, critic_one_learning.trainable_variables))
if actorupdate == True:
with tf.GradientTape() as tape: # actor net 업데이트를 위한 자동미분 (critic net 업데이트와 별개로 둠)
actions_by_learner = actor_learning(input_load,input_pv,input_others) # actor_learning을 gradient descent로 훈련시키려면, GradientTape 구문 내에서 현재 state에 대한 action Tensor를 actor_learning으로 다시 불러와야 함
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions_by_learner) # actor_learning으로 다시 불러온 action 기반으로 Q-value 계산
loss_actor = tf.reduce_mean(-Q_values_one) # 음의 Q-value 최소화, 즉 Q-value를 최대화하도록 actor를 업데이트함
grads = tape.gradient(loss_actor, actor_learning.trainable_variables)
actor_learning.optimizer.apply_gradients(zip(grads, actor_learning.trainable_variables))
actor_weights = actor_learning.weights # 원래 net의 weight 불러옴 (연산을 위해)
target_actor_weights = actor_target.weights # target net의 weight 불러옴
for i in range(len(actor_weights)): # Target net 가중치 업데이트
target_actor_weights[i] = tau * actor_weights[i] + (1 - tau) * target_actor_weights[i] # tau가 작으므로 target net이 '천천히' 업데이트됨
actor_target.set_weights(target_actor_weights) # 업데이트된 가중치로 설정
critic_one_weights = critic_one_learning.weights # 원래 net의 weight 불러옴 (연산을 위해)
target_critic_one_weights = critic_one_target.weights # target net의 weight 불러옴
for i in range(len(critic_one_weights)): # Target net 가중치 업데이트
target_critic_one_weights[i] = tau * critic_one_weights[i] + (1 - tau) * target_critic_one_weights[i] # tau가 작으므로 target net이 '천천히' 업데이트됨
critic_one_target.set_weights(target_critic_one_weights) # 업데이트된 가중치로 설정
profits_test = []
elapsedtime_test = []
max_return_test = -np.inf
count_step_fortrain = 0
bool_fortrain = False
for epoch in range(100):
if epoch > 0:
start_time = time.time()
### Train for each epoch
hour = 24
energy_batt = initialenergy_batt
for step in range(len(load_train)-25):
count_step_fortrain += 1
epsilon = max(1 - epoch / 50, 0.1)
energy_batt, reward, action = play_one_step(load_train,PV_prod_train,hour,energy_batt,epsilon,training=True)
hour += 1
if epoch > 0 and count_step_fortrain > period_step_fortrain:
training_step(batch_size,actorupdate=bool_fortrain)
count_step_fortrain = 0
bool_fortrain = not bool_fortrain # 한 번은 critic만, 한 번은 actor & target까지 전부 업데이트하는 과정을 교대로 진행
### Validation for each epoch
if epoch > 0:
testcase_actions = []
testcase_battenergy = []
epoch_return_test = 0
hour = 24 # 시작시점
energy_batt = initialenergy_batt
for step in range(len(load_test)-24):
energy_batt, reward, action = play_one_step(load_test,PV_prod_test,hour,energy_batt,0,training=False)
testcase_actions.append(action)
testcase_battenergy.append(energy_batt)
epoch_return_test += reward
hour += 1
profits_test.append(epoch_return_test)
with open('trajectory_profit_test_ddpg.txt', 'w') as f:
for line in profits_test:
f.write(f"{line}\n")
if max_return_test < epoch_return_test:
max_return_test = epoch_return_test
actor_learning.save_weights('actor_trainedmodel_ddpg.h5')
critic_one_learning.save_weights('critic_one_trainedmodel_ddpg.h5')
with open('trajectory_actions_test_ddpg.txt', 'w') as f:
for line in testcase_actions:
f.write(f"{line}\n")
with open('trajectory_battenergy_test_ddpg.txt', 'w') as f:
for line in testcase_battenergy:
f.write(f"{line}\n")
elapsed_time = time.time() - start_time
elapsedtime_test.append(elapsed_time)
print("Validation: profit of epoch {} is {}, maximum profit is {}".format(epoch,round(epoch_return_test,2),round(max_return_test,2)))
print('one epoch 수행에 {}초 걸렸습니다'.format(round(elapsed_time,2)))
with open('trajectory_time_test_ddpg.txt', 'w') as f:
for line in elapsedtime_test:
f.write(f"{line}\n")
DDPG를 통한 continuous control 결과
DDPG 훈련 결과, validation case에서의 누적 비용은 125유로이다.
놀랍게도(?), continuous control (DDPG) 의 결과가 3-action discrete control (DQN) 의 결과 (누적비용 50유로) 보다 나쁘다. 어떻게 된 걸까?
아래 그림으로 action을 비교해 보자.
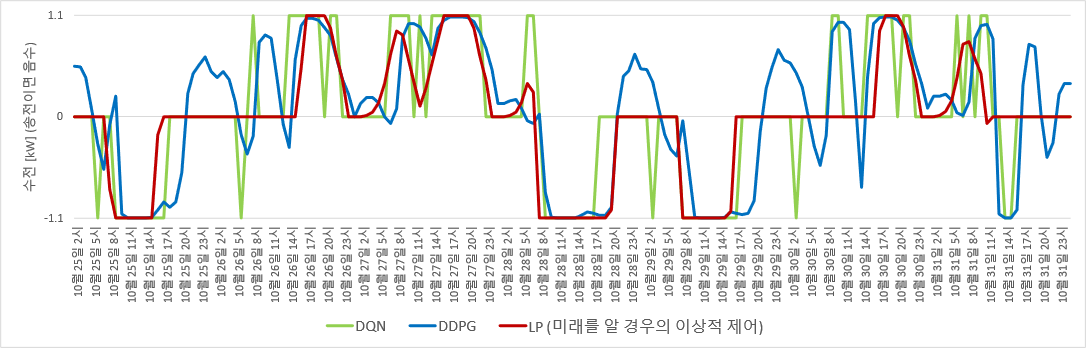 DDPG로 도출한 수전/송전 control. LP control과는 차이가 있음.
DDPG로 도출한 수전/송전 control. LP control과는 차이가 있음.
태양광 발전량이 많아 낮에 송전하는 기간의 밤 시간대에 LP와 DQN에선 action의 값이 0, 즉 idle이다. 그러나 DDPG에서는 수전을 한다. 반대로 태양광 발전량이 적어 낮에 수전하는 기간의 밤 시간대에도 LP와 DQN에선 action이 idle인데 DDPG에서는 일부 송전을 한다.
즉 LP와 DQN control에서는 수 시간 연속으로 idle인 기간에, DDPG control에서는 송전 혹은 수전을 행한다. 그런데 이것이 sub-optimal control인 것으로 보인다.
이는 state를 input으로 하는 nonlinear continuous function 근사로는, 대부분의 input에 대해 output이 0, -1, +1 셋 중 하나이고 그 외 일부 input에 대해서만 값이 -1~0 또는 0~1 사이의 값을 출력하는 function을 (LP control에서처럼) 만들어내기 어렵기 때문인 것으로 추측된다.
즉, 미래를 모두 안다고 가정했을 때의 LP control은 DDPG로 도출한 control과는 거리가 있으며 DQN으로 도출한 control에 더 가까운 형태를 띤다. 그렇기 때문에, 놀랍게도(?) Vincent의 마이크로그리드 사례에서는 DQN의 discrete control이 DDPG의 continuous control 대비 더 나은 것으로 보인다.
그러나 누군가는 이렇게 반박할 수 있다. “DDPG는 초창기 기법이다. 몇 년 뒤 Twin Delayed Deep Deterministic policy gradient (TD3)나 Soft Actor-Critic (SAC)처럼, 더 진보된 continuous control 방법들이 나왔다. 더 진보된 방법을 쓰면, 완벽한 continuous control을 얻을 것이다.”
과연 어떨까? 다음 포스팅에서 확인해 보겠다.
1) 미래를 모를 때의 '경제적' control을 위한 강화학습
2) 강화학습의 기본, Q-learning 리뷰
3) Deep Q-Network를 통한 3-action control 도출
4) DDPG를 이용한 'continuous' control 도출
5) TD3/ SAC 등 '진보된' continuous control을 쓴다면?