강화학습 기반 마이크로그리드 control - 5) TD3/ SAC 등 ‘진보된’ continuous control을 쓴다면?
Deep Deterministic Policy Gradient (DDPG) 로 도출한 수전/송전의 continuous control이, 놀랍게도(?) Vincent의 마이크로그리드 사례에서는, DQN으로 도출한 3-actions discrete control 대비 더 좋지 않았다 (3개 action들은 각각 1.1kW 수전/ 1.1kW 송전/ idle).
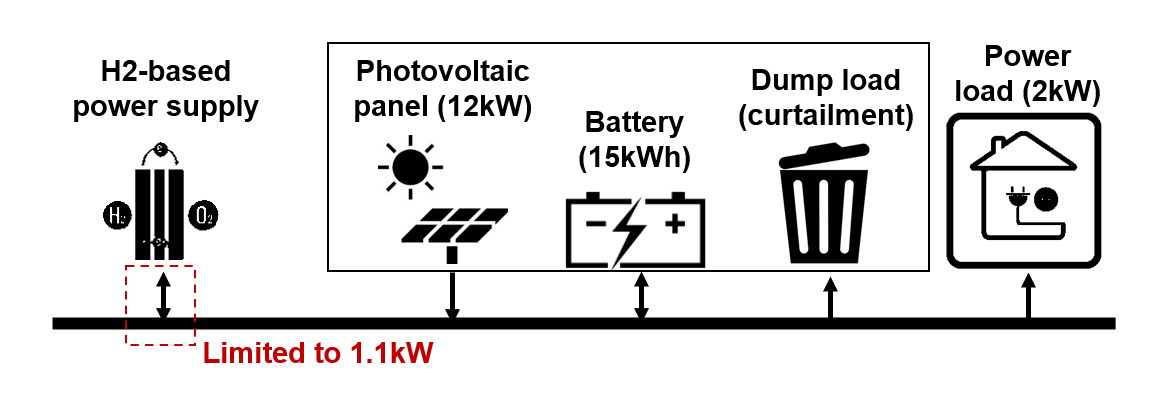 Vincent의 연구에서 가정된 마이크로그리드.
Vincent의 연구에서 가정된 마이크로그리드.
그렇다면 continuous control 도출을 위해 DDPG 이후에 개발된 더 진보된 방법을 쓴다면 어떨까?
진보된 방법들의 대표 사례들로, Twin Delayed Deep Deterministic policy gradient (TD3) 와 Soft Actor-Critic (SAC) 이 있다.
Twin Delayed DDPG (TD3)
TD3가 DDPG와 비교해 갖는 차이점은 대략 아래와 같다 (항상 그렇지만 상세한 내용은 논문 원문을 참고하자).
1) critic 신경망을 한 개가 아닌 두 개 사용한다. 그리고 $Q(s_{t+1},a_{t+1})$을 두 개의 target critic 신경망 각각에 대해 계산하고 그 중 ‘더 작은 값’을 사용한다. 마찬가지로 actor 훈련시의 목적함수 내 $Q(s_{t},a_{t})$ 또한 두 critic 신경망 각각에 대해 계산하고 그 중 ‘더 작은 값’을 사용한다. 이를 통해 Q-learning 특유의 overestimation 문제를 완화할 수 있다.
2) $a_{t+1}$을 결정 시 actor로부터 도출한 결과를 그대로 쓰는 게 아니라, clipped noise를 추가한다. 이를 통해 smoothing regularization 효과를 얻는다.
3) Critic이 여러 번 업데이트될 동안 actor는 한 번 업데이트된다. 이러한 `delayed’ policy update를 통해 value estimation의 variance를 줄인다.
TD3 훈련 코드는 아래와 같다. 코드 내 주석은 지난 포스팅의 DDPG 코드 대비 다른 부분에 대해서만 추가하였다. (GitHub Repo 링크)
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Dense, Conv1D, concatenate, Flatten
import time
### hyperparameters
actor_lr = 0.0001
critic_lr = 0.0002
tau = 0.05
rewardscalefactor = 1/6
buffer_size = 20000
batch_size = 32
discount_factor = 0.98
clippednoise_std = 0.1 # clipped noise를 생성하는 평균이 0인 정규분포의 표준편차
clippednoise_interval = 0.15 # clipped noise의 구간 설정
period_step_fortrain = 24
### microgrid system data
PV_prod_train = np.load('BelgiumPV_prod_train.npy')
PV_prod_test = np.load('BelgiumPV_prod_test.npy')
load_train = np.load('example_nondeterminist_cons_train.npy')
load_test = np.load('example_nondeterminist_cons_test.npy')
prate_h2 = 1.1
eff_h2 = 0.65
capa_batt = 15
eff_batt = 0.9
initialenergy_batt = 0.0
price_h2 = 0.1
cost_loss = 2
load_peak = 2
pv_peak = 12
inputlen_load = 24
inputlen_pv = 24
### Neural net configuration
class Critic(tf.keras.Model):
def __init__(self):
super(Critic, self).__init__()
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.input_action = Input(shape=(1))
self.concat_all = concatenate([self.flatten_conv,self.input_others,self.input_action])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_qval = Dense(1)(self.hidden_dense_2)
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others,self.input_action], outputs=[self.output_qval])
def call(self, input_load,input_pv,input_others,input_action):
return self.model((input_load,input_pv,input_others,input_action))
class Actor(tf.keras.Model):
def __init__(self):
super(Actor, self).__init__()
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.concat_all = concatenate([self.flatten_conv,self.input_others])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_action = Dense(1,activation='tanh')(self.hidden_dense_2)
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others], outputs=[self.output_action])
def call(self, input_load,input_pv,input_others):
return self.model((input_load,input_pv,input_others))
critic_one_learning = Critic()
critic_one_target = Critic()
critic_one_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.set_weights(critic_one_learning.get_weights())
critic_two_learning = Critic() # Critic NN을 2개 사용함
critic_two_target = Critic() # 두 번째 critic NN의 target net
critic_two_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_two_target.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_two_target.set_weights(critic_two_learning.get_weights())
actor_learning = Actor()
actor_target = Actor()
actor_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.set_weights(actor_learning.get_weights())
from collections import deque
replay_buffer = deque(maxlen=buffer_size)
def sample_experiences(batch_size):
indices = np.random.randint(len(replay_buffer), size=batch_size)
batch = [replay_buffer[index] for index in indices]
states, actions, rewards, next_states = [
np.array([experience[field_index] for experience in batch])
for field_index in range(4)]
return states, actions, rewards, next_states
def play_one_step(profile_load,profile_pv,hour,energy_batt,epsilon,training=False):
state = np.concatenate( (profile_load[hour-inputlen_load:hour], profile_pv[hour-inputlen_pv:hour], np.array([energy_batt])) )
if np.random.rand() < epsilon and training == True:
action = np.random.uniform(low=-1.0, high=1.0, size=1)[0]
else:
action = actor_learning(profile_load[hour-inputlen_load:hour].reshape(-1,inputlen_load,1), profile_pv[hour-inputlen_pv:hour].reshape(-1,inputlen_pv,1), np.array([energy_batt]).reshape(-1,1)).numpy()[0][0]
p_h2_send = 0
p_h2_receive = 0
if action > 0:
p_h2_receive = prate_h2*action
else:
p_h2_send = -prate_h2*action
p_load = profile_load[hour]*load_peak
p_pv = profile_pv[hour]*pv_peak
energy_batt = energy_batt*capa_batt
#p_curtail = 0
p_loss = 0
p_net_beforebatt = p_pv - p_load + p_h2_receive - p_h2_send
if p_net_beforebatt >= 0:
if capa_batt >= energy_batt + p_net_beforebatt*eff_batt:
energy_batt_after = energy_batt + p_net_beforebatt*eff_batt
else:
energy_batt_after = capa_batt
else:
if energy_batt*eff_batt >= -p_net_beforebatt:
energy_batt_after = energy_batt + p_net_beforebatt/eff_batt
else:
energy_batt_after = 0
p_loss = -p_net_beforebatt - energy_batt*eff_batt
reward = price_h2*p_h2_send*eff_h2 - price_h2*p_h2_receive/eff_h2 - cost_loss*p_loss
energy_batt_after = energy_batt_after/capa_batt
if training == True:
next_state = np.concatenate( (profile_load[hour-(inputlen_load-1):hour+1], profile_pv[hour-(inputlen_pv-1):hour+1], np.array([energy_batt_after])) )
replay_buffer.append((state, action, reward*rewardscalefactor, next_state))
return energy_batt_after, reward, action
def training_step(batch_size,actorupdate=True):
states, actions, rewards, next_states = sample_experiences(batch_size)
input_load = states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv = states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others = states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
input_load_next = next_states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv_next = next_states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others_next = next_states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
noise = np.random.normal(0,clippednoise_std,size=batch_size).reshape(-1,1)
noise = np.clip(noise, -clippednoise_interval, clippednoise_interval)
actions_by_target = actor_target(input_load_next,input_pv_next,input_others_next).numpy().reshape(-1,1) + noise # clipped noise 추가 (smoothing 효과 얻음)
actions_by_target = np.clip(actions_by_target,-1,1) # clipped noise를 추가하더라도 action이 [-1,1] 범위에 들게 제한
Q_values_one_by_target = critic_one_target(input_load_next,input_pv_next,input_others_next,actions_by_target)
Q_values_two_by_target = critic_two_target(input_load_next,input_pv_next,input_others_next,actions_by_target) # 두 번째 critic net을 사용해서 nextstate에 대한 Q-value 계산
Q_values_min_by_target = tf.math.minimum(Q_values_one_by_target, Q_values_two_by_target) # 두 Q-value들 중 작은 값을 사용 (over-estimation 문제 완화)
y = tf.stop_gradient(rewards + discount_factor * Q_values_min_by_target)
with tf.GradientTape() as tape:
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions.reshape(-1,1))
loss_critic_one = tf.reduce_mean(keras.losses.mean_squared_error(y, Q_values_one))
grads = tape.gradient(loss_critic_one, critic_one_learning.trainable_variables)
critic_one_learning.optimizer.apply_gradients(zip(grads, critic_one_learning.trainable_variables))
with tf.GradientTape() as tape:
Q_values_two = critic_two_learning(input_load,input_pv,input_others,actions.reshape(-1,1))
loss_critic_two = tf.reduce_mean(keras.losses.mean_squared_error(y, Q_values_two))
grads = tape.gradient(loss_critic_two, critic_two_learning.trainable_variables)
critic_two_learning.optimizer.apply_gradients(zip(grads, critic_two_learning.trainable_variables))
if actorupdate == True:
with tf.GradientTape() as tape:
actions_by_learner = actor_learning(input_load,input_pv,input_others)
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions_by_learner)
Q_values_two = critic_two_learning(input_load,input_pv,input_others,actions_by_learner)
Q_values_min = tf.math.minimum(Q_values_one, Q_values_two)
loss_actor = tf.reduce_mean(-Q_values_min)
grads = tape.gradient(loss_actor, actor_learning.trainable_variables)
actor_learning.optimizer.apply_gradients(zip(grads, actor_learning.trainable_variables))
actor_weights = actor_learning.weights
target_actor_weights = actor_target.weights
for i in range(len(actor_weights)):
target_actor_weights[i] = tau * actor_weights[i] + (1 - tau) * target_actor_weights[i]
actor_target.set_weights(target_actor_weights)
critic_one_weights = critic_one_learning.weights
critic_two_weights = critic_two_learning.weights
target_critic_one_weights = critic_one_target.weights
target_critic_two_weights = critic_two_target.weights
for i in range(len(critic_one_weights)):
target_critic_one_weights[i] = tau * critic_one_weights[i] + (1 - tau) * target_critic_one_weights[i]
target_critic_two_weights[i] = tau * critic_two_weights[i] + (1 - tau) * target_critic_two_weights[i]
critic_one_target.set_weights(target_critic_one_weights)
critic_two_target.set_weights(target_critic_two_weights)
profits_test = []
elapsedtime_test = []
max_return_test = -np.inf
count_step_fortrain = 0
bool_fortrain = False
for epoch in range(100):
if epoch > 0:
start_time = time.time()
### Train for each epoch
hour = 24 # 시작시점
energy_batt = initialenergy_batt
for step in range(len(load_train)-25):
count_step_fortrain += 1
epsilon = max(1 - epoch / 50, 0.1)
energy_batt, reward, action = play_one_step(load_train,PV_prod_train,hour,energy_batt,epsilon,training=True)
hour += 1
if epoch > 0 and count_step_fortrain > period_step_fortrain:
training_step(batch_size,actorupdate=bool_fortrain)
count_step_fortrain = 0
bool_fortrain = not bool_fortrain
### Validation for each epoch
if epoch > 0:
testcase_actions = []
testcase_battenergy = []
epoch_return_test = 0
hour = 24
energy_batt = initialenergy_batt
for step in range(len(load_test)-24):
energy_batt, reward, action = play_one_step(load_test,PV_prod_test,hour,energy_batt,0,training=False)
testcase_actions.append(action)
testcase_battenergy.append(energy_batt)
epoch_return_test += reward
hour += 1
profits_test.append(epoch_return_test)
with open('trajectory_profit_test_td3.txt', 'w') as f:
for line in profits_test:
f.write(f"{line}\n")
if max_return_test < epoch_return_test:
max_return_test = epoch_return_test
actor_learning.save_weights('actor_trainedmodel_td3.h5')
critic_one_learning.save_weights('critic_one_trainedmodel_td3.h5')
critic_two_learning.save_weights('critic_two_trainedmodel_td3.h5')
with open('trajectory_actions_test_td3.txt', 'w') as f:
for line in testcase_actions:
f.write(f"{line}\n")
with open('trajectory_battenergy_test_td3.txt', 'w') as f:
for line in testcase_battenergy:
f.write(f"{line}\n")
elapsed_time = time.time() - start_time
elapsedtime_test.append(elapsed_time)
print("Validation: profit of epoch {} is {}, maximum profit is {}".format(epoch,round(epoch_return_test,2),round(max_return_test,2)))
print('one epoch 수행에 {}초 걸렸습니다'.format(round(elapsed_time,2)))
with open('trajectory_time_test_td3.txt', 'w') as f:
for line in elapsedtime_test:
f.write(f"{line}\n")
Soft Actor-Critic (SAC)
SAC에서는 ‘stochastic’ actor를 가정한다. 즉 actor는 특정 확률분포로부터 action을 도출한다. $a_{t} \sim \pi_{\phi}(a|s_{t})$ 인 것이다.
Actor의 직접적인 출력은 정규분포의 평균값 그리고 표준편차의 로그값이고, 이로부터 정의되는 정규분포로부터 샘플을 뽑거나 (training) 평균값을 (validation) 뽑는다. 만약 bounded action인 경우 tanh kernel을 추가해서 action을 결정한다.
Stochastic actor를 쓰기 때문에, DQN/ DDPG/ TD3에서 그랬던 것처럼 hand-crafted noise를 따로 추가하지 않아도 자동으로 훈련 과정에서 exploration이 된다는 장점이 있다.
그리고 SAC에서는 신경망들을 훈련 시 `최대화’ 대상 목적함수에 entropy term $-\alpha \text{log} \pi_{\phi}(a|s_{t}) $ 이 추가된다 (로그확률값은 actor를 call 할 때 받아옴).
정보이론에서 Entropy는 음의 확률에 로그확률을 곱한 값이고 목적함수는 평균을 의미하므로 앞에 확률값이 생략된 것으로 보면 위 term은 entropy를 의미한다. Entropy가 클수록 해당 확률분포가 균등분포에 가까워지므로, 결과적으로 exploration을 장려하게 된다.
$\alpha$는 temperature parameter로, 클수록 entropy의 최대화에 가중치를 많이 줘서 균등분포에 더 가까워진다. SAC에서는 $\alpha$를 사전에 고정된 값으로 결정하지 않고, $\alpha$가 minimum expected entropy 조건 하의 return 최대화 문제의 dual problem의 Lagrangian multiplier임에 착안해 그 값을 변경해 나간다. 그러므로 $\alpha$의 초기값은 사용자가 결정하지만, 그 값은 훈련을 거치면서 지속적으로 수정된다. (역시 상세 내용은 논문 원문을 참고하자.)
SAC 훈련 코드는 아래와 같다 (코드 작성에 참고한 포스팅). 코드 내 주석은 지난 포스팅의 DDPG 코드 대비 다른 부분에 대해서만 추가하였다.
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
import tensorflow_probability as tfp
from tensorflow import keras
from keras.layers import Input, Dense, Conv1D, concatenate, Flatten
import time
### hyperparameters
alpha_lr = 0.00005 # temperature parameter에 대한 learning rate
actor_lr = 0.0005
critic_lr = 0.001
tau = 0.05
alpha_initial = 0.1 # temperature parameter의 초기값
target_entropy = -tf.constant(1, dtype=tf.float32) # 1은 DoF of action
rewardscalefactor = 1 # SAC가 reward scale에 민감하므로 잘 선택해야 함: reward가 너무 낮으면 너무 exploration만 해버리고, reward가 너무 높으면 처음엔 학습이 빨리 되는 것 같아 보이지만 poor local minima로 수렴함이 알려짐
buffer_size = 20000
batch_size = 32
discount_factor = 0.98
period_step_fortrain = 24
### microgrid system data
PV_prod_train = np.load('BelgiumPV_prod_train.npy')
PV_prod_test = np.load('BelgiumPV_prod_test.npy')
load_train = np.load('example_nondeterminist_cons_train.npy')
load_test = np.load('example_nondeterminist_cons_test.npy')
prate_h2 = 1.1
eff_h2 = 0.65
capa_batt = 15
eff_batt = 0.9
initialenergy_batt = 0.0
price_h2 = 0.1
cost_loss = 2
load_peak = 2
pv_peak = 12
inputlen_load = 24
inputlen_pv = 24
### Neural net configuration
class Critic(tf.keras.Model):
def __init__(self):
super(Critic, self).__init__()
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.input_action = Input(shape=(1))
self.concat_all = concatenate([self.flatten_conv,self.input_others,self.input_action])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_qval = Dense(1)(self.hidden_dense_2)
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others,self.input_action], outputs=[self.output_qval])
def call(self, input_load,input_pv,input_others,input_action):
return self.model((input_load,input_pv,input_others,input_action))
class Actor(tf.keras.Model):
def __init__(self):
super(Actor, self).__init__()
self.input_load = Input(shape=(inputlen_load,1))
self.input_pv = Input(shape=(inputlen_pv,1))
self.hidden_conv_load = Conv1D(16, 2, activation='relu')(self.input_load)
self.hidden_conv_pv = Conv1D(16, 2, activation='relu')(self.input_pv)
self.concat_conv = concatenate([self.hidden_conv_load,self.hidden_conv_pv],axis=2)
self.hidden_conv_concat = Conv1D(16,2,activation='relu')(self.concat_conv)
self.flatten_conv = Flatten()(self.hidden_conv_concat)
self.input_others = Input(shape=(1))
self.concat_all = concatenate([self.flatten_conv,self.input_others])
self.hidden_dense_1 = Dense(50,activation='relu')(self.concat_all)
self.hidden_dense_2 = Dense(20,activation='relu')(self.hidden_dense_1)
self.output_action_mean = Dense(1,activation='linear')(self.hidden_dense_2) # 정규분포의 평균
self.output_action_stddev = Dense(1,activation='linear')(self.hidden_dense_2) # 정규분포의 표준편차
self.model = keras.Model(inputs=[self.input_load,self.input_pv,self.input_others], outputs=[self.output_action_mean,self.output_action_stddev])
def call(self, input_load,input_pv,input_others,training=True):
mu, logsigma = self.model((input_load,input_pv,input_others)) # 정규분포의 평균, 로그표준편차
sigma = tf.exp(logsigma) # 로그표준편차를 표준편차로 변환
dist = tfp.distributions.Normal(mu, sigma) # 정규분포 정의
if training == True: # Training 시
action_temp = dist.sample() # 정규분포로부터 임의로 샘플 뽑아서 action 결정
else: # Validation 시
action_temp = mu # Validation 시에는 mean action으로 (deterministic action)
action = tf.tanh(action_temp) # tanh activation function을 이용한 bounded action 구현
logprob_temp = dist.log_prob(action_temp)
logprob = logprob_temp - tf.reduce_sum(tf.math.log(1 - action**2 + 1e-16), axis=1,
keepdims=True) # log-probability 반환
return action, logprob
critic_one_learning = Critic()
critic_one_target = Critic()
critic_one_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_one_target.set_weights(critic_one_learning.get_weights())
critic_two_learning = Critic()
critic_two_target = Critic()
critic_two_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_two_target.compile(optimizer=keras.optimizers.Adam(learning_rate=critic_lr))
critic_two_target.set_weights(critic_two_learning.get_weights())
actor_learning = Actor()
actor_target = Actor()
actor_learning.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.compile(optimizer=keras.optimizers.Adam(learning_rate=actor_lr))
actor_target.set_weights(actor_learning.get_weights())
alpha = tf.Variable(alpha_initial, dtype=tf.float32) # temperature parameter 정의
alpha_optimizer = tf.keras.optimizers.Adam(learning_rate=alpha_lr)
actor_weight_temp = actor_learning.get_weights()
critic_one_weight_temp = critic_one_learning.get_weights()
critic_two_weight_temp = critic_two_learning.get_weights()
from collections import deque
replay_buffer = deque(maxlen=buffer_size)
def sample_experiences(batch_size):
indices = np.random.randint(len(replay_buffer), size=batch_size)
batch = [replay_buffer[index] for index in indices]
states, actions, rewards, next_states = [
np.array([experience[field_index] for experience in batch])
for field_index in range(4)]
return states, actions, rewards, next_states
def play_one_step(profile_load,profile_pv,hour,energy_batt,training=False):
state = np.concatenate( (profile_load[hour-inputlen_load:hour], profile_pv[hour-inputlen_pv:hour], np.array([energy_batt])) )
action, _ = actor_learning(profile_load[hour-inputlen_load:hour].reshape(-1,inputlen_load,1), profile_pv[hour-inputlen_pv:hour].reshape(-1,inputlen_pv,1), np.array([energy_batt]).reshape(-1,1),training=training)
action = action.numpy()[0][0]
p_h2_send = 0
p_h2_receive = 0
if action > 0:
p_h2_receive = prate_h2*action
else:
p_h2_send = -prate_h2*action
p_load = profile_load[hour]*load_peak
p_pv = profile_pv[hour]*pv_peak
energy_batt = energy_batt*capa_batt
# p_curtail = 0
p_loss = 0
p_net_beforebatt = p_pv - p_load + p_h2_receive - p_h2_send
if p_net_beforebatt >= 0:
if capa_batt >= energy_batt + p_net_beforebatt*eff_batt:
energy_batt_after = energy_batt + p_net_beforebatt*eff_batt
else:
energy_batt_after = capa_batt
# p_curtail = (energy_batt + p_net_beforebatt*eff_batt - capa_batt)/eff_batt
else:
if energy_batt*eff_batt >= -p_net_beforebatt:
energy_batt_after = energy_batt + p_net_beforebatt/eff_batt
else:
energy_batt_after = 0
p_loss = -p_net_beforebatt - energy_batt*eff_batt
reward = price_h2*p_h2_send*eff_h2 - price_h2*p_h2_receive/eff_h2 - cost_loss*p_loss
energy_batt_after = energy_batt_after/capa_batt
if training == True:
next_state = np.concatenate( (profile_load[hour-(inputlen_load-1):hour+1], profile_pv[hour-(inputlen_pv-1):hour+1], np.array([energy_batt_after])) )
replay_buffer.append((state, action, reward*rewardscalefactor, next_state))
return energy_batt_after, reward, action
def training_step(batch_size,actorupdate=True):
states, actions, rewards, next_states = sample_experiences(batch_size)
input_load = states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv = states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others = states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
input_load_next = next_states[:,0:inputlen_load].reshape(-1,inputlen_load,1)
input_pv_next = next_states[:,inputlen_load:(inputlen_load+inputlen_pv)].reshape(-1,inputlen_pv,1)
input_others_next = next_states[:,(inputlen_load+inputlen_pv)].reshape(-1,1)
actions_by_target, logprobs_actions_target = actor_target(input_load_next,input_pv_next,input_others_next)# action 뿐 아니라 로그확률도 불러옴, 로그확률은 entropy term에 사용됨
Q_values_one_by_target = critic_one_target(input_load_next,input_pv_next,input_others_next,actions_by_target)
Q_values_two_by_target = critic_two_target(input_load_next,input_pv_next,input_others_next,actions_by_target)
Q_values_min_by_target = tf.math.minimum(Q_values_one_by_target, Q_values_two_by_target)
y = tf.stop_gradient(rewards + discount_factor * (Q_values_min_by_target - alpha*logprobs_actions_target)) # entropy term이 추가됨됨
with tf.GradientTape() as tape:
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions.reshape(-1,1)) #
loss_critic_one = tf.reduce_mean(keras.losses.mean_squared_error(y,Q_values_one))
grads = tape.gradient(loss_critic_one, critic_one_learning.trainable_variables)
critic_one_learning.optimizer.apply_gradients(zip(grads, critic_one_learning.trainable_variables))
with tf.GradientTape() as tape:
Q_values_two = critic_two_learning(input_load,input_pv,input_others,actions.reshape(-1,1))
loss_critic_two = tf.reduce_mean(keras.losses.mean_squared_error(y,Q_values_two))
grads = tape.gradient(loss_critic_two, critic_two_learning.trainable_variables)
critic_two_learning.optimizer.apply_gradients(zip(grads, critic_two_learning.trainable_variables))
if actorupdate == True:
with tf.GradientTape() as tape:
actions_by_learner, logprobs_actions = actor_learning(input_load,input_pv,input_others)
Q_values_one = critic_one_learning(input_load,input_pv,input_others,actions_by_learner)
Q_values_two = critic_two_learning(input_load,input_pv,input_others,actions_by_learner)
Q_values_min = tf.math.minimum(Q_values_one, Q_values_two)
loss_actor = tf.reduce_mean(alpha*logprobs_actions - Q_values_min)
grads = tape.gradient(loss_actor, actor_learning.trainable_variables)
actor_learning.optimizer.apply_gradients(zip(grads, actor_learning.trainable_variables))
with tf.GradientTape() as tape: # temperature parameter의 업데이트
actions_by_learner, logprobs_actions = actor_learning(input_load,input_pv,input_others)
loss_alpha = tf.reduce_mean(-alpha*(logprobs_actions+target_entropy))
grads = tape.gradient(loss_alpha, [alpha])
alpha_optimizer.apply_gradients(zip(grads, [alpha]))
actor_weights = actor_learning.weights
target_actor_weights = actor_target.weights
for i in range(len(actor_weights)):
target_actor_weights[i] = tau * actor_weights[i] + (1 - tau) * target_actor_weights[i]
actor_target.set_weights(target_actor_weights)
critic_one_weights = critic_one_learning.weights
critic_two_weights = critic_two_learning.weights
target_critic_one_weights = critic_one_target.weights
target_critic_two_weights = critic_two_target.weights
for i in range(len(critic_one_weights)):
target_critic_one_weights[i] = tau * critic_one_weights[i] + (1 - tau) * target_critic_one_weights[i]
target_critic_two_weights[i] = tau * critic_two_weights[i] + (1 - tau) * target_critic_two_weights[i]
critic_one_target.set_weights(target_critic_one_weights)
critic_two_target.set_weights(target_critic_two_weights)
profits_test = []
elapsedtime_test = []
max_return_test = -np.inf
count_step_fortrain = 0
bool_fortrain = False
for epoch in range(100):
if epoch > 0:
start_time = time.time()
### Train for each epoch
hour = 24
energy_batt = initialenergy_batt
for step in range(len(load_train)-25):
count_step_fortrain += 1
energy_batt, reward, action = play_one_step(load_train,PV_prod_train,hour,energy_batt,training=True)
hour += 1
if epoch > 0 and count_step_fortrain > period_step_fortrain:
training_step(batch_size,actorupdate=bool_fortrain)
count_step_fortrain = 0
bool_fortrain = not bool_fortrain
actor_weight_temp = actor_learning.get_weights()
critic_one_weight_temp = critic_one_learning.get_weights()
critic_two_temp = critic_two_learning.get_weights()
### Validation for each epoch
if epoch > 0:
testcase_actions = []
testcase_battenergy = []
epoch_return_test = 0
hour = 24
energy_batt = initialenergy_batt
for step in range(len(load_test)-24):
energy_batt, reward, action = play_one_step(load_test,PV_prod_test,hour,energy_batt,training=False)
testcase_actions.append(action)
testcase_battenergy.append(energy_batt)
epoch_return_test += reward
hour += 1
profits_test.append(epoch_return_test)
with open('trajectory_profit_test_sac.txt', 'w') as f:
for line in profits_test:
f.write(f"{line}\n")
if max_return_test < epoch_return_test:
max_return_test = epoch_return_test
actor_learning.save_weights('actor_trainedmodel_sac.h5')
critic_one_learning.save_weights('critic_one_trainedmodel_sac.h5')
critic_two_learning.save_weights('critic_two_trainedmodel_sac.h5')
with open('trajectory_actions_test_sac.txt', 'w') as f:
for line in testcase_actions:
f.write(f"{line}\n")
with open('trajectory_battenergy_test_sac.txt', 'w') as f:
for line in testcase_battenergy:
f.write(f"{line}\n")
elapsed_time = time.time() - start_time
elapsedtime_test.append(elapsed_time)
print("Validation: profit of epoch {} is {}, maximum profit is {}".format(epoch,round(epoch_return_test,2),round(max_return_test,2)))
print('one epoch 수행에 {}초 걸렸습니다'.format(round(elapsed_time,2)))
print('Temperature parameter 값은 {}입니다.'.format(alpha.numpy()))
with open('trajectory_time_test_sac.txt', 'w') as f:
for line in elapsedtime_test:
f.write(f"{line}\n")
SAC 훈련에서 주의할 점은, 가끔 $\alpha$가 NaN이 되기도 한다는 것이다. (솔직히 아직은 이유를 모르겠다… 사실 이 부분은 100% 이해를 한 게 아니라서, 위 reference page에서 한 방식을 그대로 쓴 것이다.) $\alpha$가 NaN이 되면 더 이상 훈련이 되지 않으니, learning rate를 더 줄이거나 한 후 처음부터 다시 훈련을 시켜야 한다.
TD3/ SAC를 통한 continuous control 결과
결과를 보면, TD3 control에서는 낮 송전 기간에 쭉 최대송전에 가깝게 하지 않고 송전량을 줄였다가 다시 늘리는 패턴이 보인다. 한편 SAC control에서는 최대송전과 최대수전을 하는 경우가 거의 없다.
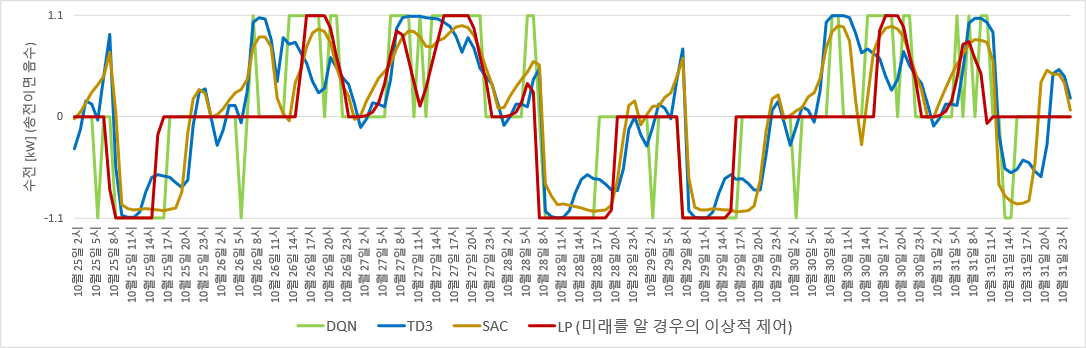 TD3/ SAC로 도출한 수전/송전 control. LP control과는 차이가 있음.
TD3/ SAC로 도출한 수전/송전 control. LP control과는 차이가 있음.
TD3와 SAC으로 도출한 control 적용 시 validation case에 대한 누적 비용은 각각 85유로, 118유로이다. 이는 DDPG control (125유로) 보다는 조금 나은 결과지만, 여전히 DQN control (50유로) 에 뒤진다.
Vincent의 마이크로그리드 사례에서는, 미래를 안다는 가정 하에 도출한 LP solution에서의 action이 (엄밀히는 continuous지만) 거의 discrete에 가까운 모습이다. 그러므로, action을 state의 continuous function으로 근사하는 DDPG/ TD3/ SAC보다는, discrete function으로 근사하는 DQN이 더 나은 것으로 추정된다.
심지어 이는 시뮬레이션으로 계산되는 마이크로그리드의 누적비용 측면에서만 생각한 것이며, 계산 시간까지 고려하면 DQN의 computational efficiency가 DDPG/ TD3/ SAC 대비 훨씬 높다.
실제로 에너지기술연구원에서 히트펌프 제어기를 심층강화학습으로 훈련시킨 연구에서도 (아래 Youtube 영상), SAC 기반 continuous control을 연구과정에서 시도하기는 했으나 최종적으로는 DQN으로 도출한 discrete control을 사용 및 논문화하였다 (히트펌프의 경우 여러 대를 설치 후 매 시간별로 몇 대나 가동할 것이냐를 결정하는 discrete control이 가능하기도 하다).
나가며
데이터 사이언스에서 ‘Data Generating Process (DGP)에 맞는 방법을 써라’ 라는 격언이 있는데, 이번 사례도 이와 유사한 교훈을 주는 사례인 것 같다.
미래를 모두 안다는 가정 하에 선형계획법으로 얻은 optimal solution에서의 action이 discrete action과 상당히 유사함을, 강화학습 계산 전에 미리 알 수 있었다. 그렇다면 이 문제에 있어 더 맞는 강화학습 방법은 discrete control 방법이며, 굳이 continuous control 방법을 시도해도 discrete 대비 더 나은 결과를 얻지 못하는 것이 놀랍지 않은 것이다.
(사족: 그런데, 사실 Vincent의 마이크로그리드 사례처럼 계통으로부터의 수전/송전 한도가 ‘peak 부하 밑으로’ 제한되어 있는 경우가 결코 흔치는 않을 것이다. 솔직히 말하면, 실제 현실에서 일반적인 case라기보다는, DQN 적용이 용이하도록 어느 정도 꾸며낸 case라는 느낌을 받는다.
실제로는 열병합발전기/ 냉난방설비 등 제어 가능한 설비의 출력을 action으로 두고, 계통으로부터의 수전/송전은 action에 따라 자동으로 결정되는 환경변수들로 두는 것이 더 합리적으로 보인다. 다만 이는 강화학습으로 안정적인 economic control을 도출하기가 쉽지 않아 보이는데, 이에 관련된 논문을 향후 찾아볼 생각이다.
-> 전기 뿐 아니라 열 수요를 고려하는 multi-energy system의 ‘일반적인’ 구성에 대해 설비 별 economic control을 DDPG로 도출하는 연구를 발견했다. 조만간 이 연구 복원을 시도해서, 성공하면 포스팅을 올릴 계획이다.)
1) 미래를 모를 때의 '경제적' control을 위한 강화학습
2) 강화학습의 기본, Q-learning 리뷰
3) Deep Q-Network를 통한 3-action control 도출
4) DDPG를 이용한 'continuous' control 도출
5) TD3/ SAC 등 '진보된' continuous control을 쓴다면?