건축물 별 월별 에너지 사용량 데이터셋 - 1) 모든 월에 대한 통합 및 표제부와의 결합 후 SQLite DB화
필자의 박사과정 졸업에 결정적인 역할을 했던 데이터셋이 있다. 건축물 별 월별 에너지 사용량 데이터다. 각 지번 주소 단위의 개별 비주거용 건물별로 특정 월에 소비한 전기와 가스의 양을 kWh 단위로 기록한 데이터셋이다.
어떤 건물의 1년 12개월 간 월별 전기 사용량과 가스 사용량은, 대부분 아래 그림과 같은 형태를 띤다.
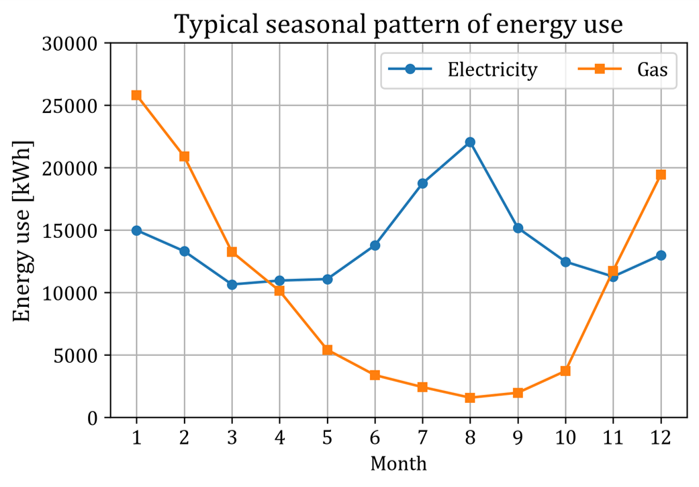 특정 건물의 1월부터 12월까지의 전기 사용량과 가스 사용량 그래프.
특정 건물의 1월부터 12월까지의 전기 사용량과 가스 사용량 그래프.
전기 사용량은 7월/ 8월 즉 여름에 크고, 가스 사용량은 1월/ 2월/ 12월 즉 겨울에 큰 걸 볼 수 있다.
지번별 에너지 사용량 데이터
이러한 개별 건물의 월별 에너지 사용량 데이터는, 국토교통부의 건축데이터 민간개방 시스템에서 제공한다.
 건축데이터 민간개방 시스템의 지번별 에너지 사용량 데이터 목록.
건축데이터 민간개방 시스템의 지번별 에너지 사용량 데이터 목록.
각각이 수십(가스)~수백(전기) MB의 텍스트 파일이며, 구분자는 $|$ 이다. 이를 엑셀로 열어보면 아래 그림과 같다.
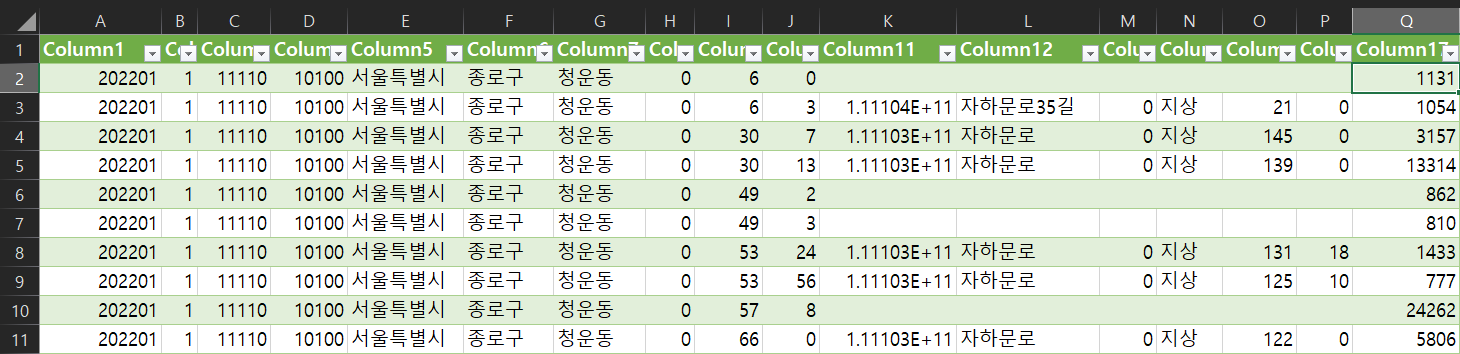 2022년 1월 전기 사용량에 대한 데이터셋, E~J열이 건물 주소, Q열이 2022년 1월의 에너지 사용량이다.
2022년 1월 전기 사용량에 대한 데이터셋, E~J열이 건물 주소, Q열이 2022년 1월의 에너지 사용량이다.
해당 데이터셋은 필자의 박사과정 중반기였던 2015년 말에 공개되었다. 필자는 해당 데이터셋을 이용해 공공건축물 신재생에너지 의무화 정책이 민간건물로까지 확대될 경우의 영향을 분석하고 및 도시 단위의 대규모 적용 시 영향을 예측하는 기법에 대한 연구를 수행해 박사학위를 받았고, 이 연구를 소재로 Energy와 Applied Energy에 제1저자 논문도 게재했다.
또한 최근에는, 위 데이터셋을 또 이용해 개별 건축물 내 월별 에너지 사용량의 결합확률분포를 모델링하는 연구를 수행하고 외부 발표를 하기도 했다 (MDSA 기사글).
 2023년 5월 12일 데이터사이언스경영학회에서 발표중인 필자.
2023년 5월 12일 데이터사이언스경영학회에서 발표중인 필자.
다만, 이 데이터셋을 제대로 활용하려면 몇 가지 사전 작업을 거쳐야 했다. 먼저 모든 월의 전기/도시가스 사용량들을 통합하고, 각 건축물 지번 별 속성 (각 건물별 연면적/ 용도/ 층수/ 건축연수/ 재질 등) 정보를 담은 데이터셋인 표제부와 결합을 해야 했다. 그리고 누락 데이터, 모양이 이상한 데이터, outlier 등을 제거해야 했다.
이번 포스팅은 에너지 사용량 데이터와 표제부를 Python의 pandas를 이용해 결합하고 SQL DB로 저장했던 과정에 대한 기록이다.
각 월별 에너지 사용량 데이터들의 통합 (1년 단위)
지번별 월별 에너지 사용량 데이터는 각 월별로 흩어져 있는데, 먼저 공통된 연도의 월별 사용량 자료들을 Python의 pandas를 이용해 하나로 합쳤다. 2022년 1월의 전기 사용량 데이터 파일의 이름을 $\texttt{elec_202201.txt}$라 할 때, 2022년의 1~12월 전기 사용량과 가스 사용량 데이터들을 하나로 합치는 코드는 아래와 같다.
# -*- coding: utf-8 -*-
import pandas as pd
import settings
filelist = ['elec_202201','elec_202202','elec_202203','elec_202204','elec_202205','elec_202206','elec_202207','elec_202208','elec_202209','elec_202210','elec_202211','elec_202212',
'gas_202201','gas_202202','gas_202203','gas_202204','gas_202205','gas_202206','gas_202207','gas_202208','gas_202209','gas_202210','gas_202211','gas_202212']
colname = ['useYm','rnum','sigunguCd','bjdongCd','sido','sigungu','bjdong','platGbCd','bun','ji','naRoadCd','naRoad','naUgrndCd','naUgrnd','naMainBun','naSubBun','useQty']
count = 0
for filename in filelist:
print(count+1)
data = pd.read_csv(settings.ENERGY_ROOT+'\\{}.txt'.format(filename),sep='|',header=None,names=colname,encoding='cp949',)
df_temp= pd.DataFrame()
df_temp['address'] = data['sido'].astype(str) +" "+ data['sigungu'].astype(str) +" "+ data["bjdong"].astype(str) +" "+ data["bun"].astype(str) +"-"+ data["ji"].astype(str)+"번지|"+data['sigunguCd'].astype(str)+"|"+data['bjdongCd'].astype(str)+"|"+data['bun'].astype(str)+"|"+data['ji'].astype(str) # 한 개 column만을 outer join 기준으로 하기 위해 코드까지 같이 넣음
df_temp['address'] = df_temp['address'].str.replace('-0','') # ji가 0인 경우 데이터에는 0으로 되어 있으나, 주소에 -0 이 나타나지 않게끔
df_temp['{}'.format(filename)] = data['useQty']
df_temp = df_temp.drop_duplicates(['address']) # 주소가 중복인 항들은 전부 제거 (중복인 항들은 에너지 사용량이 모두 동일 수치인 것 확인함)
if(count==0):
df = df_temp
else:
df = pd.merge(left = df , right = df_temp, how = "outer", on = "address") # 한 월에 대해서라도 사용량 있는 주소는 모두 포함하므로 outer
del data, df_temp
count += 1
# 모든 월에 대해 join되었으므로 주소텍스트와 주소코드를 나눔
df['addresstxt'] = df['address'].str.split('|').str.get(0) # 표제부에서 사용하는 주소 string과 같음
df['sigunguCd'] = df['address'].str.split('|').str.get(1)
df['bjdongCd'] = df['address'].str.split('|').str.get(2)
df['bun'] = df['address'].str.split('|').str.get(3)
df['ji'] = df['address'].str.split('|').str.get(4)
del df['address']
df = df[['addresstxt','sigunguCd','bjdongCd','bun','ji','elec_202201','elec_202202','elec_202203','elec_202204','elec_202205','elec_202206','elec_202207','elec_202208','elec_202209','elec_202210','elec_202211','elec_202212','gas_202201','gas_202202','gas_202203','gas_202204','gas_202205','gas_202206','gas_202207','gas_202208','gas_202209','gas_202210','gas_202211','gas_202212']]
df = df.drop_duplicates(['addresstxt']) # 주소가 중복인 항들은 전부 제거 (중복인 항들은 에너지 사용량이 모두 동일 수치인 것 확인함)
df.to_csv(settings.CSV_ROOT+'\\monthlyenergy_2022.csv',sep=',',encoding='utf-8-sig')
filelist에 각 파일명을 미리 적어놓고, colname에 각 열 이름을 코드 내에서 어떻게 명시할 지 적어놓았다 (각 열에 대한 설명은, 같이 다운받을 수 있는 데이터셋_정의서 파일에 있다). 그리고 모든 데이터들을 반복문을 이용해 순서대로 불러온다.
파일 내 건물 주소명은 기본적으로 시/구/번/지 로 쪼개져 있는데, 표제부에서는 주소명이 합쳐져 있으므로 표제부 주소와 결합할 것을 상정하고 표제부와 같은 포맷이 되게, address 칼럼을 새로 만든다. address 같은 행들은 조사 결과 모두 같은 에너지 사용량 값들을 갖고 있어서, 단순 중복으로 간주하고 $\texttt{drop_duplicates}$로 삭제하였다.
이렇게 address 칼럼을 각 데이터셋에 대해 만들고, 모든 데이터셋을 address 기준으로 outer join해 합친 데이터셋이 df가 되도록 하였다. Outer join을 한 이유는 한 개 데이터셋에라도 있는 건물은 우선 포함시키기 위함이다. 그리고 df에서 필요한 칼럼들만 남긴 후 csv 파일로 저장하였다. .
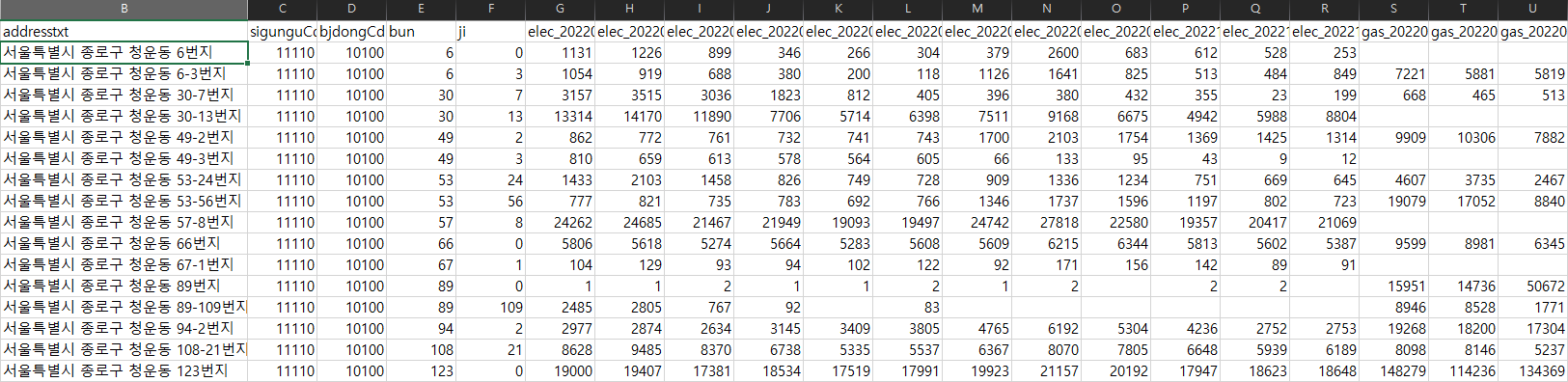 2022년의 모든 월의 전기/가스 사용량들을 통합 후 csv 파일로 저장함.
2022년의 모든 월의 전기/가스 사용량들을 통합 후 csv 파일로 저장함.
어떤 건물들은 가스 사용량이 모든 월에 대해 없는데, 이는 해당 건물이 도시가스를 공급받지 않기 때문이다 (해당 건물 내 일부 부대시설(음식점 등)이 LPG 가스를 사용하거나 할 수는 있지만, 그 양은 알 수 없다).
에너지 사용량 데이터와 표제부 결합
다음으로, 모든 월의 에너지 사용량 통합 데이터를 표제부와 합치고 SQL DB로 저장한다.


 표제부에는 각 건물 별 주소/ 면적/ 건폐율/ 용적률/ 용도/ 재질/ 층수/ 사용허가일 등 정보가 있음.
표제부에는 각 건물 별 주소/ 면적/ 건폐율/ 용적률/ 용도/ 재질/ 층수/ 사용허가일 등 정보가 있음.
대한민국 내 모든 건물들에 대한 표제부 정보를 포함하는 수 GB의 텍스트 파일을 다운받을 수 있다. 각 열의 설명은 같이 다운받을 수 있는 데이터구조 파일에 있다 (그런데 실제 데이터의 순서와 다른 경우도 있어서, 결국 직접 확인해야 했다…).
이 파일의 표제부 데이터를 위에서 만든 csv 파일 내 에너지 사용량 데이터와 합치고, 필요한 칼럼들을 모아서 SQLite DB로 저장하는 코드는 아래와 같다.
# -*- coding: utf-8 -*-
import pandas as pd
import settings
# 각 column의 의미는 pyojedata 폴더의 데이터구조.xls 참고
colname = ['column_01', 'column_02', 'column_03', 'column_04', 'column_05', 'addresstxt', 'column_07', 'bldgname', 'sigunguCd', 'bjdongCd', 'column_11', 'bun', 'ji', 'column_14', 'column_15', 'column_16', 'column_17', 'column_18', 'column_19', 'column_20', 'column_21', 'column_22', 'column_23', 'column_24', 'column_25', 'sitearea', 'buildingarea', 'coverageratio', 'floorarea', 'netfloorarea', 'voltolotratio', 'structureCd', 'structure', 'structuresub', 'principaluseCd', 'principaluse', 'subuse', 'roofCd', 'roof', 'roofsub', 'num_household', 'num_gagu', 'column_43', 'num_level', 'num_level_below', 'column_46', 'column_47', 'column_48', 'column_49', 'totalfloorarea', 'column_51', 'column_52', 'column_53', 'column_54', 'column_55', 'column_56', 'column_57', 'column_58', 'column_59', 'column_60', 'approvaldate', 'column_62', 'column_63', 'column_64', 'column_65', 'column_66', 'column_67', 'efficiencygrade', 'efficiencyrate', 'efficiencyscore', 'greengrade', 'greenscore', 'column_73', 'column_74', 'column_75', 'column_76', 'column_77']
# 표제부 불러오기
data = pd.read_csv(settings.PYOJE_ROOT+'\\pyojetable.txt',sep='|',header=None,names=colname,encoding='CP949')
# 미리 netfloorarea에 대해 내림차순 정렬해서, 추후 같은 번지에 여러 건물이 있을 경우 중복제거 후 용도가 netfloorarea가 가장 큰 항목의 용도가 되게 함
data = data.sort_values(by=['netfloorarea'], ascending=False)
# 중복주소들에 대해 값을 합칠 항목들 (연면적, 세대수 등) 을 합치기
data_tosum = data[["addresstxt","sitearea","buildingarea","floorarea","netfloorarea","num_household","num_gagu"]]
data_tosum = data_tosum.groupby('addresstxt').sum()
# 중복주소들에 대해 값을 합치지 않을 항목들은 하나만 남김
data_todrop = data[["addresstxt","structureCd","structure","structuresub","principaluseCd","principaluse","subuse","roofCd","roof","approvaldate","coverageratio","voltolotratio","num_level"]]
data_todrop = data_todrop.drop_duplicates(['addresstxt'])
# 표제부 항목들을 outer join으로 합치기
data = pd.merge(left = data_tosum , right = data_todrop, how = "outer", on = "addresstxt")
del data_tosum, data_todrop
# 월별 에너지 사용량 데이터 불러오기
energydata = pd.read_csv(settings.CSV_ROOT+'\\monthlyenergy_2022.csv',sep=',')
# 표제부 항목들과 월별 에너지 사용량 데이터를 left join으로 합치기 (건물 속성 정보가 있는 경우에만)
resultdata = pd.merge(left = data , right = energydata, how = "left", on = "addresstxt")
del data, energydata
# pandas df에서 생기는 기본 axis column 필요없으므로 삭제
resultdata = resultdata.drop(['Unnamed: 0'],axis='columns')
# addresstxt가 null인 row들 없애기 (SQL에서 addresstxt에 대한 not null 제약 만족하도록)
resultdata = resultdata.dropna(subset=['addresstxt'])
# addresstxt가 중복인 경우 하나만 남기고 없애기 (SQL에서 addresstxt에 대한 primary key 제약 만족하도록_
resultdata = resultdata.drop_duplicates(['addresstxt'])
# netfloorarea(용적률산정용연면적, 열인덱스 4)가 floorarea(연면적, 열인덱스 3)보다 큰 경우 잘못된 데이터이므로 수정:
# 대지면적 * 용적률 이 계산되면서 그 값이 연면적보다 작으면 그 값을 쓰고,
# 대지면적 혹은 용적률이 누락되어 0이 나오거나 그 값이 연면적보다 크면 연면적을 씀
for i in range(resultdata.shape[0]):
if resultdata.iloc[i,3] < resultdata.iloc[i,4]: # 연면적 < 용적률산정면적 이면
if resultdata.iloc[i,1]*resultdata.iloc[i,17]/100 > 0 and resultdata.iloc[i,1]*resultdata.iloc[i,17]/100 < resultdata.iloc[i,3]:
resultdata.iloc[i,4] = resultdata.iloc[i,1]*resultdata.iloc[i,17]/100
else:
resultdata.iloc[i,4] = resultdata.iloc[i,3]
# CSV 파일로 저장
resultdata.to_csv(settings.CSV_ROOT+'\\monthlyenergy_2022_pyoje.csv',sep=',',encoding='utf-8-sig')
# SQLite query 실행
import sqlite3
conn = sqlite3.connect('db_monthlyenergy_pyoje.db') # .db 잊어버리지 말 것
cur = conn.cursor()
with conn:
sql_create = """
create table monthlyenergy_2022_pyoje
(addresstxt text primary key not null, /* 주소, primary key로써 고유해야 함 */
sitearea numeric, /* 대지면적 [m2] */
buildingarea numeric, /* 건축면적 [m2] */
floorarea numeric, /* 연면적 [m2] */
netfloorarea numeric, /* 용적률산정용연면적 [m2] */
voltolotratio numeric, /* 용적률 */
principaluse text, /* 주용도코드명 */
subuse text, /* 기타용도 */
principaluseCd integer, /* 주용도코드 */
coverageratio numeric, /* 건폐율 */
num_household integer, /* 세대수 */
num_gagu integer, /* 가구수 */
structureCd integer, /* 구조코드 */
structure text, /* 구조코드명 */
structuresub text, /* 기타구조 */
roofCd integer, /* 지붕코드 */
roof text, /* 지붕코드명 */
roofsub text, /* 기타지붕 */
num_level integer, /* 지상층수 */
approvaldate text, /* 사용승인일 */
sigunguCd integer, /* 시군구코드 */
bjdongCd integer, /* 법정동코드 */
bun integer, /* 번 */
ji integer, /* 지 */
elec_01 numeric, /* 월별 전기 사용량 [kWh] */
elec_02 numeric,
elec_03 numeric,
elec_04 numeric,
elec_05 numeric,
elec_06 numeric,
elec_07 numeric,
elec_08 numeric,
elec_09 numeric,
elec_10 numeric,
elec_11 numeric,
elec_12 numeric,
gas_01 numeric, /* 월별 가스 사용량 [kWh] */
gas_02 numeric,
gas_03 numeric,
gas_04 numeric,
gas_05 numeric,
gas_06 numeric,
gas_07 numeric,
gas_08 numeric,
gas_09 numeric,
gas_10 numeric,
gas_11 numeric,
gas_12 numeric
)
"""
cur.execute(sql_create)
resultdata.to_sql('monthlyenergy_2022_pyoje', conn, index=False, if_exists='replace')
에너지 사용량 데이터에서 중복 주소를 제거했기 때문에, 표제부에서도 중복주소는 제거해야 한다 (이 경우 주소가 primary key가 된다).
같은 지번주소 내에 실제로 여러 건물들이 있기도 하는데, 대지면적이나 연면적 (모든 층의 바닥면적들의 합) 등의 칼럼들에 대해서는 모든 건물들의 값을 다 더하면 된다 (이는 코드 내 $\texttt{data_tosum}$ 변수 정의에서 $\texttt{groupby}$와 $\texttt{sum}$으로 구현함).
그러나, 건물용도 (근린생활/ 업무/ 판매/ 의료 등) 또는 층수 등은 합칠 수 없는데, 미리 $\texttt{sort_values}$ 함수를 이용해 연면적 기준으로 내림차순 정렬을 해 놓음으로써 주소 중복 제거 시 건물용도나 층수 등이 가장 연면적이 큰 건물 기준으로 결정되게 했다 (코드 내 $\texttt{data_todrop}$ 변수 정의에서 $\texttt{drop_duplicates}$로 구현함). 참고로 표제부의 여러 칼럼들 중 필요한 칼럼들만 가져오는 것도 여기에 반영되어 있다.
표제부의 주소 중복 제거를 처리한 후, 에너지사용량 csv 파일을 불러오고, 표제부와 에너지사용량을 주소 기준으로 outer join으로 합친다. 그 결과물인 resultdata dataframe을 SQL table로 만드는 create table 쿼리를 sqlite3 패키지와 to_sql 함수를 이용해 실행했다.
서울 소재 건물들에 대해 구성한 SQLite DB의 스크린샷들은 아래와 같다.



 2022년의 모든 월의 전기/가스 사용량들을 표제부와 결합하고 SQLite DB로 저장함.
2022년의 모든 월의 전기/가스 사용량들을 표제부와 결합하고 SQLite DB로 저장함.
필자는 서울 소재 건물들에 대한 연구 수행을 위해, 아래 코드를 통해 전체 SQLite DB로부터 서울 내 건물들 중 전기 사용량 및 연면적 값의 누락이 없는 행들만으로 table을 만들고 이를 별도의 DB 및 table로 저장였다.
# -*- coding: utf-8 -*-
# SQLite DB로부터 서울 소재이며 월별 전기 및 용적률산정연면적 누락이 없는 데이터들만 df로 불러오기
your_query = """
select * from monthlyenergy_2022_pyoje
where addresstxt like '서울특별시%'
and elec_01 not null
and elec_02 not null
and elec_03 not null
and elec_04 not null
and elec_05 not null
and elec_06 not null
and elec_07 not null
and elec_08 not null
and elec_09 not null
and elec_10 not null
and elec_11 not null
and elec_12 not null
and netfloorarea not null
and netfloorarea > 0
"""
import pandas as pd
import sqlite3
conn = sqlite3.connect("db_monthlyenergy_pyoje.db") # .db 잊어버리지 말 것
cur = conn.cursor()
with conn:
df_result = pd.DataFrame(cur.execute(your_query).fetchall())
df_result.columns = [x[0] for x in cur.description] # add column names to the table
conn.close()
conn_export = sqlite3.connect("db_monthlyenergy_seoul.db")
df_result.to_sql('seoul_2022', conn_export, index=False, if_exists='append') # 별도의 SQLite DB로 저장
df_result.to_csv('seoul_2022.csv',sep=',',encoding='utf-8-sig')
1) 모든 월에 대한 통합 및 표제부와의 결합 후 SQLite DB화
2) 월별 사용 추이가 이상한 data point 제거
3) 월별 사용량 크기가 이상한 data point 제거
4) 결측치 추정: 조건부 다변량정규분포를 이용해서