건축물 별 월별 에너지 사용량 데이터셋 - 4) 결측치 추정: 조건부 다변량정규분포를 이용해서
건축물 별 월별 에너지 사용량 데이터셋에는 종종 값의 누락, 즉 결측치가 있다. 결측치가 있는 row들은 실제로는 활용이 불가능한데 용량만 차지하는 골칫덩어리이다. 대신 결측치를 ‘합리적으로’ 메꿀 수 있다면, 쓸 수 있는 데이터의 양이 많아지므로 분석의 정확도가 올라갈 것이다.
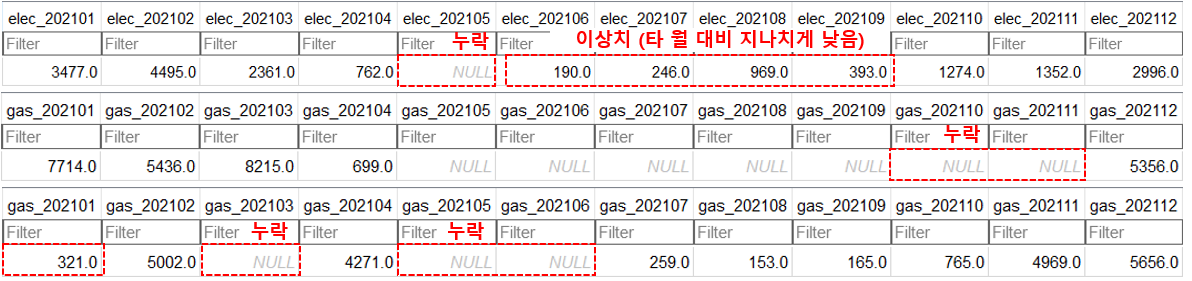 월별 사용량 데이터셋의 결측치 및 비정상적인 값들. 참값에 대한 합리적인 추정이 필요하다.
월별 사용량 데이터셋의 결측치 및 비정상적인 값들. 참값에 대한 합리적인 추정이 필요하다.
Naive한 중간값 기반 추정의 문제점
순진하게(?) 생각하면, 시간에 따른 데이터의 결측치는 앞 시간과 뒷 시간의 두 값 간 중간값으로 메꾸면 될 것 같다. 즉 시점 $t$의 어떤 값 $x[t]$가 누락될 경우, 추정을 $\hat{x}[t] = (x[t-1]+x[t+1])/2$ 로 하는 것이다 ($\hat{x}$는 $x$의 추정량).
그런데, 아래와 같은 상황에서는 어떻게 할 것인가?
1) 시간 $t-1,t,t+1$의 데이터가 누락되었다. 그러면 $\hat{x}[t-1]$, $\hat{x}[t]$, $\hat{x}[t+1]$를 어떻게 결정할 것인가? $x[t-2]$와 $x[t+2]$ 간 차이를 삼등분할 때의 값으로?
그런데 참값 $x[t-1]$, $x[t]$, $x[t+1]$들이 실제로도 그렇게 ‘균등하게 증가/감소’한다는 보장이 있나?
2) 마지막 시간을 $T$라 할 때 $x[T-1]$, $x[T]$가 누락되었다. $x[T+1]$은 없는데 어떻게 하지?
3) 누군가가 $\hat{x}[t] = ((x[t-2]+x[t-1]+x[t+1]+x[t+2])/4$ 로 추정하면 안 되냐고 물으면 어떻게 대답할 것인가?
아마 어떻게 하기가 힘들 것이다. 이는 특별한 프로세스 없이 ‘그냥’ 추정하려 했기 때문에 생긴 문제다.
명확한 프로세스로 추정치를 계산하고 그 과정을 남에게 잘 설명할 수 있어야, 결측치를 메꿀 뿐 아니라 그 메꾼 데이터를 실제로 프로젝트에 쓸 수 있다.
필자의 결측치 추정 모델 (공분산 고려)
바람직한 방법은, 데이터가 가진 통계적 특성을 반영해 모델로 만들고 해당 모델로 참값을 추정하는 것이다.
아래 그림은 필자의 모델 기반으로 결측치를 추정하는 예시이다.
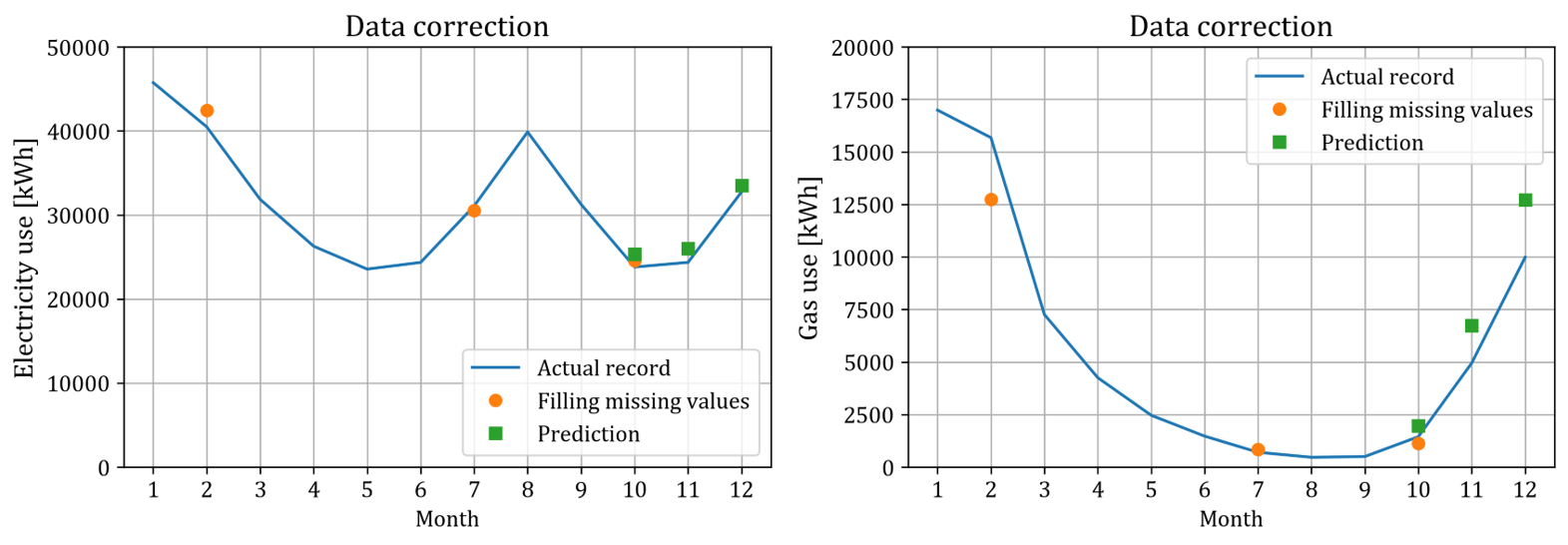 필자의 모델 기반으로 결측치를 추정한 예시. 추정값들 (원, 네모) 이 참값 (실선) 에 가깝다.
필자의 모델 기반으로 결측치를 추정한 예시. 추정값들 (원, 네모) 이 참값 (실선) 에 가깝다.
파란 실선은, 어떤 건물의 12개월 간 실제 월별 에너지 사용량이다. 주황색 원은 실제 월별 사용량 값들 중 2, 7, 10월 값들이 누락되었다고 가정할 때, ‘나머지 월들의 값들 기반으로’ 결측치를 추정한 결과이다. 초록색 네모는 실제 월별 사용량 값이 9월까지만 주어졌다고 가정할 때, 10, 11, 12월 값들에 대한 예측을 수행한 결과이다.
결측치 추정이 꽤나 잘 이루어졌다고 생각되지 않는가?
위 추정 방법에 대한 ‘상세한’ 설명은, 아래 링크의, 필자가 (사)데이터사이언스경영학회에 기고한 글들을 참고하길 바란다.
건축물 별 월간 전기/가스 사용량 예측:결합확률분포 모델 기반 예측 ②
건축물 별 월간 전기/가스 사용량 예측:결합확률분포 모델 기반 예측 ③
건축물 별 월간 전기/가스 사용량 예측:결합확률분포 모델 기반 예측 ④
건축물 별 월간 전기/가스 사용량 예측:결합확률분포 모델 기반 예측 ⑤
핵심은, 12개월간의 월별 전기 사용량을 ‘12차원 벡터’로 보고 (이 시리즈의 두 번째 글에서도 그랬듯), ‘비슷한 건물들의’ 벡터들이 따르는 다변량 정규분포를 추정하는 것이다. 건물 수가 많으면, 충분히 쓸 수 있는 분포를 만들 수 있다.
이 때, ‘다변량’정규분포이므로 ‘공’분산까지 추정하는 것이 핵심이다. ‘공’분산이란, ‘다른 건물들의 평균적 사용량 대비 1월에 에너지를 많이 쓰는 건물에선 2, 3, …, 12월에도 에너지를 많이 쓸 것이고, 그 반대도 성립함을 의미한다.
기고글에 쓴 예시는 다음과 같다.
어떤 두 업무용 건물이 있는데 연면적과 층수 등의 규모도 비슷하고 사용 연수도 비슷하고 건물 재질도 비슷하다. 그러나 한 건물은 직원들이 매일 야근하고 주말 특근도 종종 하는데다 에어컨을 많이 틀어 전기 사용량이 많은 반면, 또 다른 건물은 직원들이 매일 정시에 퇴근하며 에너지 절약을 중시하는 경향이 있다.
그러면 전자에서는 7월 전기 사용량이 비슷한 타 건물들의 평균적인 사용량 대비 클 것이고, 후자에서는 작을 것이다. 그러면 ‘일반적으로’ 8월 전기 사용량도 전자에서는 크고, 후자에서는 작을 것이다. 즉 7월 사용량과 8월 사용량 간에 ‘상관관계’가 있는 것이다.
그렇다면 8월 전기 사용량이 누락된 경우, 타 건물들의 평균적 8월 사용량이 얼마인지, 그리고 해당 건물의 7월 전기 사용량이 평균 대비 얼마나 크거나 작은지 정보를 이용해, 8월 전기 사용량을 합리적으로 추정할 수 있다.
평균과 ‘공’분산 반영을 위한 조건부 다변량정규분포
12개월간의 월별 전기 사용량 중 사용량이 누락된 월의 사용량들에 대한 벡터를 $y_1$, 사용량 값을 알고 있는 월의 사용량들에 대한 벡터를 $y_2$라 하자. 이 때, 벡터 $ y = [y_1^{\top}, y_2^{\top}]^{\top}$ 가 근사적으로 다변량정규분포 (MultiVariate Normal, MVN) 를 따른다고 보고 (그렇게 볼 수 있다), 아래와 같이 식을 쓰자.
\begin{align} y \vert X = \text{MVN} \left( \begin{bmatrix} \mu_1 \newline \mu_2 \end{bmatrix}, \begin{bmatrix} \Sigma_{11} & \Sigma_{12} \newline \Sigma_{21} & \Sigma_{22} \end{bmatrix} \right) \notag \end{align}
위에서 $X$는 연면적/ 용도/ 층수/ 사용연수 등 건물의 특성, 즉 평균적 사용량 추정을 위한 설명변수이다. 해당 설명변수들을 이용한 회귀분석의 잔차에 대한 상관계수를 구하면, 건물 규모/ 용도/ 층수/ 사용연수 효과 통제 후의 상관관계를 볼 수 있다.
MVN의 첫 번째 인수는 평균 벡터이고, 두 번째 인수는 공분산 행렬이다. 공분산 행렬의 대각성분은 각 월별 사용량의 분산을 나타내고, 비대각성분은 해당하는 두 월의 사용량들 간 공분산을 나타낸다.
필자가 구했던 아래 상관계수표를 보면, 상관계수가 0.8~0.9 정도로 1에 가깝다. 즉, 서로 다른 두 월의 사용량들 간 상관관계가 뚜렷하다.
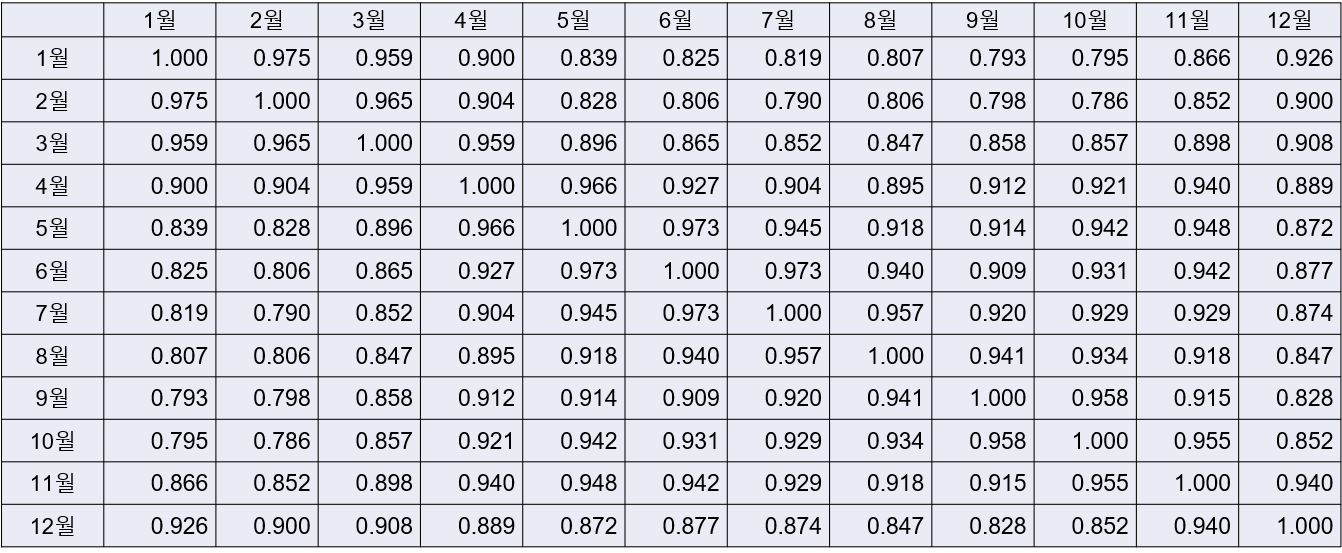 서울 내 업무용 건물들의, 1~12월의 전기 사용량 간 상관계수 (건물 규모/ 용도/ 층수/ 사용연수 효과를 통제한 후의 값임).
서울 내 업무용 건물들의, 1~12월의 전기 사용량 간 상관계수 (건물 규모/ 용도/ 층수/ 사용연수 효과를 통제한 후의 값임).
다변량정규분포의 공분산 행렬은 위 상관계수표 기반으로 추정된다.
그리고 누락된 월들의 사용량 벡터 $y_1$을 확률변수로 둘 때, 그 외 월들의 사용량 벡터가 $a$로 주어진 경우 이를 ‘조건부로’ 하는 ‘조건부’ 다변량정규분포는 아래와 같다.
$p(y_1 \vert y_2=a) = \text{MVN}(\mu_1 + \Sigma_{12} \Sigma_{22}^{-1}(a-\mu_2), \Sigma_{11}-\Sigma_{12} \Sigma_{22}^{-1}\Sigma_{21})$
위 조건부 다변량정규분포의 평균 $\mu_1 + \Sigma_{12} \Sigma_{22}^{-1}(a-\mu_2)$ 가, 결측치 $y_1$에 대한 추정량이다.
시계열 모델을 쓰지 않은 이유
이쯤에서 어느 정도 배경지식이 있는 독자라면, ‘ARIMA 등 시계열 모델을 쓰면 되지 않나? 왜 저런 생소한 방법으로 하지?’ 라는 질문을 할 수 있다.
ARIMA 등 시계열 모델은 기본적으로 ‘하나의 개체’ 에 대한 분석을 전제로 한다. 즉 건물 하나에 대해 오랜 시간 축적한 월별 사용량 자료를 갖고 있고 ‘해당 건물에 대해서만’ 결측치를 메꿀 것이라면, ARIMA 모델은 적절한 선택이다. 그러나, 수천~수만 개 건물들 각각에 대해 ARIMA 모델을 다 만들 수는 없다.
그래서 필자는 ‘하나의 건물 뿐 아니라 비슷한 여러 건물들’ 에 대해 하나의 모델로 결측치를 메꾸고자 했다. ‘여러 건물들’ 에 쓸 수 있는 모델을 만들기 위해, ARIMA 대신 본문의 접근을 택했다.
더 수준이 높은 독자라면, ‘패널 데이터 분석’을 쓰면 되지 않나?’ 라고 질문할 수 있다. 패널 데이터 분석은 ‘여러 개체’의 ‘시간적 변화’를 고려한 회귀분석이기 때문이다.
사실 필자가 위 다변량정규분포의 평균 $\mu = [\mu_1^{\top},\mu_2^{\top}]^{\top}$ 를 구하기 위해 사용한 방법이, 패널데이터에서 배우는 Seemingly Unrelated Regression (SUR) 이다. SUR을 쓰면 ‘같은 건물에 대한’ 서로 다른 두 월의 사용량 간 상관관계를 고려해 모델을 추정할 수 있다. (공분산행렬은 SUR 모델의 잔차들로 추정하였다.)
특히 필자의 데이터셋 기준으로 SUR에서는, 같은 월의 서로 다른 건물들에 대한 사용량 추정의 오차항들이 ‘동일한 분포에서 독립적으로 추출되었다 (independent and identically distributed, i.i.d.) 고 가정하지, 서로 다른 월에 대해서는 이러한 가정을 하지 않는다. 이를테면 봄/가을의 전기 사용량의 편차보다는, 여름 전기 사용량의 편차가 당연히 더 클 것이다.
그러나 패널데이터에서 주로 쓰이는 임의효과 (random effect) 또는 고정효과 (fixed effect) 모형의 경우, 모든 월에 대한 오차항들의 ‘등’분산을 가정한다. 이는 위 전기 사용량 편차 예시를 보면, 현실과 맞지 않는 가정이다.
그러므로 서로 다른 월의 에너지 사용량 각각의 분산이 다른 필자의 데이터셋에서는, SUR을 사용하여 적절한 패널 데이터 분석을 수행한 것으로 볼 수 있다.
1) 모든 월에 대한 통합 및 표제부와의 결합 후 SQLite DB화
2) 월별 사용 추이가 이상한 data point 제거
3) 월별 사용량 크기가 이상한 data point 제거
4) 결측치 추정: 조건부 다변량정규분포를 이용해서