데이터 결측치 처리 예시 - 주택의 분 단위 전기 부하 자료
스마트그리드 분야에 머신러닝/ 딥러닝/ 강화학습 기법이 어떻게 적용되는지에 대해 자세한 정보를 제공해주는 책으로 ‘스마트그리드 빅데이터 분석의 활용’ 이 있다.
이 책의 7장 ‘딥러닝을 이용한 스마트그리드 데이터 분석’ 에서는, 널리 알려진 backpropagation 기반 ANN 모델 뿐 아니라 (Factored Conditional) Restricted Boltzmann Machine 기반 모델을 이용해 전력 부하를 예측하는 연구를 소개한다.
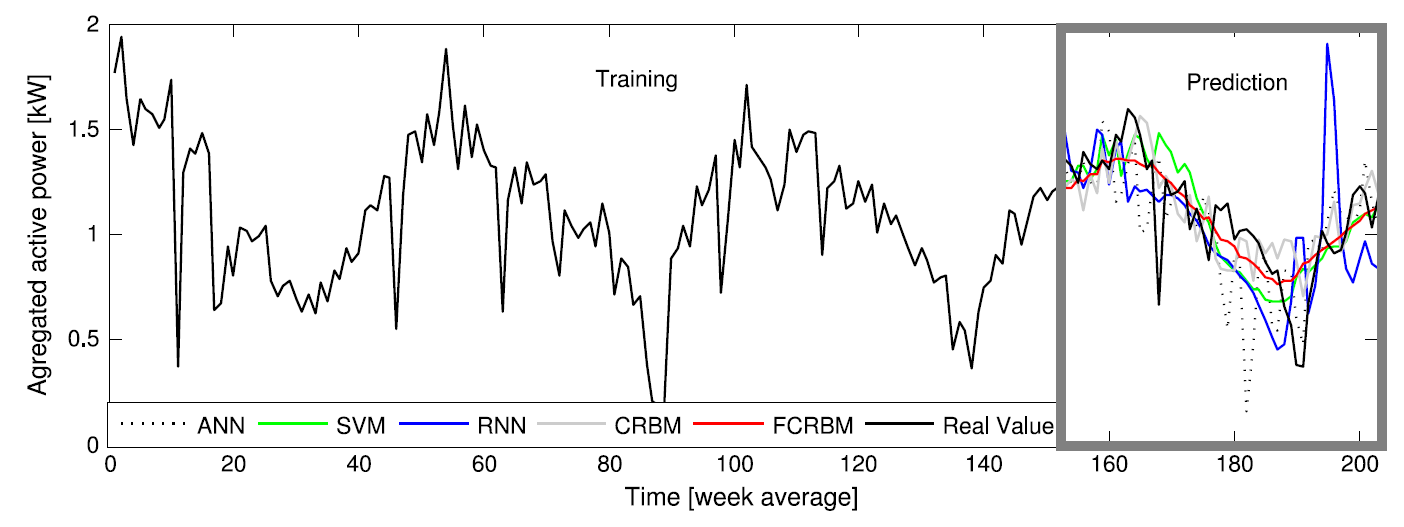 Mocanu의 논문에서 1주일 평균 전력 부하를 여러 기법들로 예측한 결과.
Mocanu의 논문에서 1주일 평균 전력 부하를 여러 기법들로 예측한 결과.
해당 연구에서 사용한 데이터는, 프랑스 내 특정 가구의 전기 부하를 1분 단위로 총 4년에 가까운 기간 동안 측정한 데이터이다.
이 포스팅은, 해당 데이터를 Python을 이용한 분석에 사용할 수 있도록 전처리하는 과정을 기록한 것이다.
SQLite DB로 변환
먼저 다운받은 txt 파일을 SQL DB 파일로 변환한다.
# -*- coding: utf-8 -*-
import pandas as pd
data = pd.read_csv('household_power_consumption.txt',sep=';')
import sqlite3
conn = sqlite3.connect('db_powerconsumption.db')
cur = conn.cursor()
with conn:
sql_create = """
create table Individualhousehold
(date text,
time text,
global_active_power numeric,
global_reactive_power numeric,
voltage numeric,
global_intensity numeric,
sub_metering_1 integer,
sub_metering_2 integer,
sub_metering_3 integer
)
"""
cur.execute(sql_create)
data.to_sql('Individualhousehold', conn, index=False, if_exists='append')
결측치 메꾸기
다음으로 결측치를 메꾼다. 원본 파일 및 SQL table을 불러온 파일에는 결측치가 ?로 표기되어 있다.
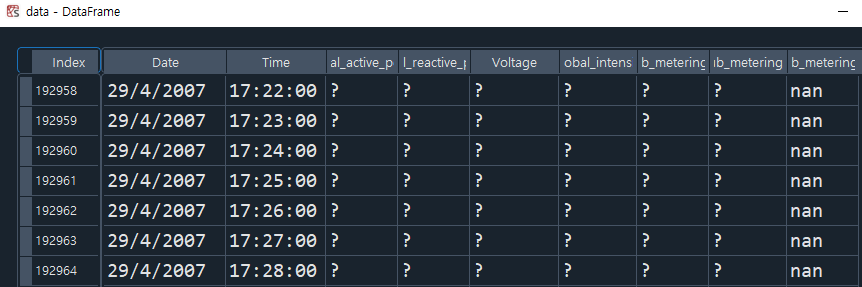 결측치가 ?로 표시되어 있음.
결측치가 ?로 표시되어 있음.
결측치를 메꾸는 코드는 다음과 같다.
# -*- coding: utf-8 -*-
# SQLite DB로부터 분별 유효전력 데이터 불러오기
your_query = """
select date, time, global_active_power from Individualhousehold
"""
import pandas as pd
import sqlite3
import datetime
conn = sqlite3.connect("db_powerconsumption.db") # .db 까먹지 말 것
cur = conn.cursor()
with conn:
df = pd.DataFrame(cur.execute(your_query).fetchall())
df.columns = [x[0] for x in cur.description]
conn.close()
# 데이터 타입이 object이므로 이를 float로 변경, 일부 값들이 ?이므로 먼저 str로 변경 후 0으로 대체 후 float로 변경
df.dtypes
df['global_active_power'] = df['global_active_power'].astype(str).replace('?','0').astype(float)
df['datetime'] = df['date'] +' ' + df['time']
df['datetime'] = pd.to_datetime(df['datetime'],format ='%d/%m/%Y %H:%M:%S')
df = df[['datetime','global_active_power']]
# ?이었던 (그리고 임시로 0으로 바뀐) 데이터 imputation: 논문에서는 타 년도의 같은 시점의 값의 평균으로 함
list_year = [2006,2007,2008,2009,2010]
is_dropped = df[df['global_active_power']==0] # ?이었던 행만 모음
for i in range(is_dropped.shape[0]):
num_for_impute = [] # 각 누락시점별로 타 년도의 같은 시점의 전기사용량을 모을 임시리스
for y in list_year:
if is_dropped.iloc[i,0].date().year != y: # 누락시점의 연도가 아닌 경우
temp_dt = datetime.datetime(year=y,
month=is_dropped.iloc[i,0].date().month,
day=is_dropped.iloc[i,0].date().day,
hour=is_dropped.iloc[i,0].time().hour,
minute=is_dropped.iloc[i,0].time().minute)
if len(df[df['datetime']==temp_dt]) > 0: # 그 연도에 해당 날짜가 있으면
if df[df['datetime']==temp_dt].iloc[0,1] >0: # 그 데이터가 0(누락)이 아니면
num_for_impute.append(df[df['datetime']==temp_dt].iloc[0,1]) # 해당 연도의 그 시점의 전력사용량 데이터를 임시리스트에 저장
df.loc[df['datetime']==is_dropped.iloc[i,0],'global_active_power'] = round(sum(num_for_impute) / len(num_for_impute),3) # 타년도 같은시점의 전력사용 데이터들의 평균값을 임시리스트로부터 계산, 소수점 셋째자리에서 반올림한 후 impute
print(i+1)
connn = sqlite3.connect("db_powerconsumption.db")
df.to_sql('active_corrected_Individualhousehold', connn, index=False, if_exists='append') # 별도의 SQLite DB로 저장
Pandas dataframe으로 불러올 경우 모든 칼럼들의 데이터타입이 object이기 때문에, 전처리를 하려면 데이터타입을 변경해야 한다.
우선 전기부하의 경우 결측치가 ?으로 되어 있으므로, 먼저 데이터타입을 string으로 바꾼 후 ?를 0으로 바꾸고 나서 다시 데이터타입을 float으로 바꿨다.
날짜와 시간의 경우, 원본 데이터에서는 날짜와 시간이 두 칼럼으로 분리되어 있지만 필자는 한번에 처리하기 위해 이를 하나로 합쳤다. 그리고 데이터타입을 datetime으로 바꿨다. (Python에서 날짜와 시간을 다루는 datetime 라이브러리를 불러와야 함)
논문에서는 특정 시점의 결측치를, 타 년도의 같은 시점 (같은 월/ 일/ 시간/ 분) 의 값들의 산술평균으로 대체했다. (참고로 이 데이터에는 특정 시점의 전기부하 값의 누락은 있어도, 시점 자체의 누락은 없다, 즉 시작 시점부터 끝 시점까지의 모든 1분 간격 시간들이 각 row로써 존재한다.)
이를 수행하기 위해, is_dropped에 누락 시점들을 모으고, 데이터셋에 해당 누락 시점과 연도만 다르고 나머지는 같은 시간이 각 연도별로 있는지, 있다면 전기부하 값이 0이 아닌지를 확인해서 그 값들을 num_for_impute에 모으고 평균을 내서 결측치를 대체한다.
기간별 평균 데이터로 변환
마지막으로, 결측치를 대체한 데이터셋을 논문 내 시나리오 (15분 평균, 1시간 평균, 1주일 평균) 에 따라 쓸 수 있도록 시나리오별 timestep 단위 평균 데이터를 만든다.
# -*- coding: utf-8 -*-
# SQLite DB로부터 분별 유효전력 데이터 불러오기
your_query = """
select * from active_corrected_Individualhousehold
"""
import pandas as pd
import numpy as np
import sqlite3
conn = sqlite3.connect("db_powerconsumption.db") # .db 까먹지 말 것
cur = conn.cursor()
with conn:
df = pd.DataFrame(cur.execute(your_query).fetchall())
df.columns = [x[0] for x in cur.description]
conn.close()
df['datetime'] = pd.to_datetime(df['datetime'],format ='%Y-%m-%d %H:%M:%S')
df.dtypes
# 15분 평균 데이터 생성
# 먼저, 시작을 0분/ 15분/ 30분/ 45분 중 하나로, 끝을 14분/ 29분/ 44분/ 59분 중 하나로 맞추기
df_temp = df[df['datetime'] >='2006-12-16 17:30:00'] # 데이터의 시작시점(2006-12-16 17:24:00) 에 가장 가까운 0분/15분/30분/45분
df_temp = df_temp[df_temp['datetime'] <='2010-11-26 20:59:00'] # 데이터의 종료시점(20010-11-26 21:02:00) 에 가장 가까운 14분/39분/44분/59분, 우변에 df_temp 가 아니라 df로 착각하지 않도록 주의
activepower_avg_temp = df_temp['global_active_power'].to_numpy().reshape((-1,15)).mean(axis=1) # mean(axis=1) 로 평균내기
# 1시간 평균 데이터 생성
# 먼저, 시작을 0분, 끝을 59분으로 맞추기
df_temp = df[df['datetime'] >='2006-12-16 18:00:00']
df_temp = df_temp[df_temp['datetime'] <='2010-11-26 20:59:00']
activepower_avg_temp = df_temp['global_active_power'].to_numpy().reshape((-1,60)).mean(axis=1)
# 1주일 평균 데이터 생성
# 시작일을 2006년 12월 17일(일요일) 0시 0분으로, 끝을 2010년 11월 20일(토요일) 23시 59분으로 맞추기
df_temp = df[df['datetime'] >='2006-12-17 00:00:00']
df_temp = df_temp[df_temp['datetime'] <='2010-11-20 23:59:00']
activepower_avg_temp = df_temp['global_active_power'].to_numpy().reshape((-1,60*24*7)).mean(axis=1)